
AAAI 2021最佳论文 | Informer:比Transformer更有效的长时间序列预测方法——Transformer进阶(一)

结合作者之一zhang shuai在AI drive上分享的PPT,来梳理下Informer模型有什么过人之处。
背景
序列预测在很多场景上都有重要的应用,比如:股市、机器人动作、人体位置、天气、供应链以及新冠疫情传播等。


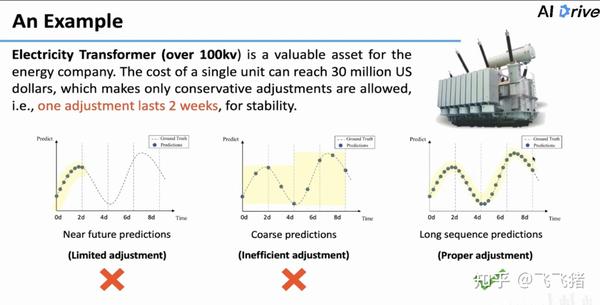
在我国,存在很多的大型变压器,这些变压器用于对我国各地电量做调配,变压器造假昂贵,一般单台造价上亿,它的设置一般不允许频繁调整,一般调一次要持续用两周,通过这种持续较长时间的调整,保持整个供电系统的稳定。因此,我们需要对未来较长一段时间的负载做出估计,这样才能确定一个调整的范围。
目前大体有三种预测思路:
- 近期预测(near future predictions): 预测较短一段时间,虽然精度较高,但预测时间太短;
- 粗粒度预测(coarse predictions):对未来较长一段时间进行预测,但是精度很低,只能预测大致趋势;
- 长时序列预测(long sequence predictions):需要的预测方法,既精细,预测时间又长。
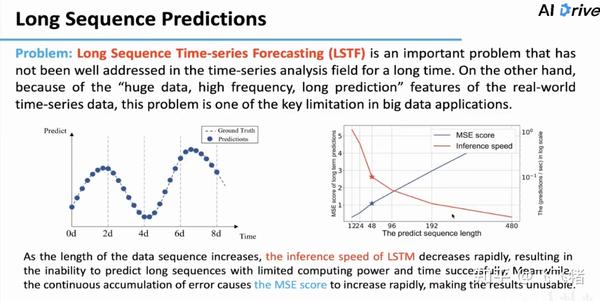
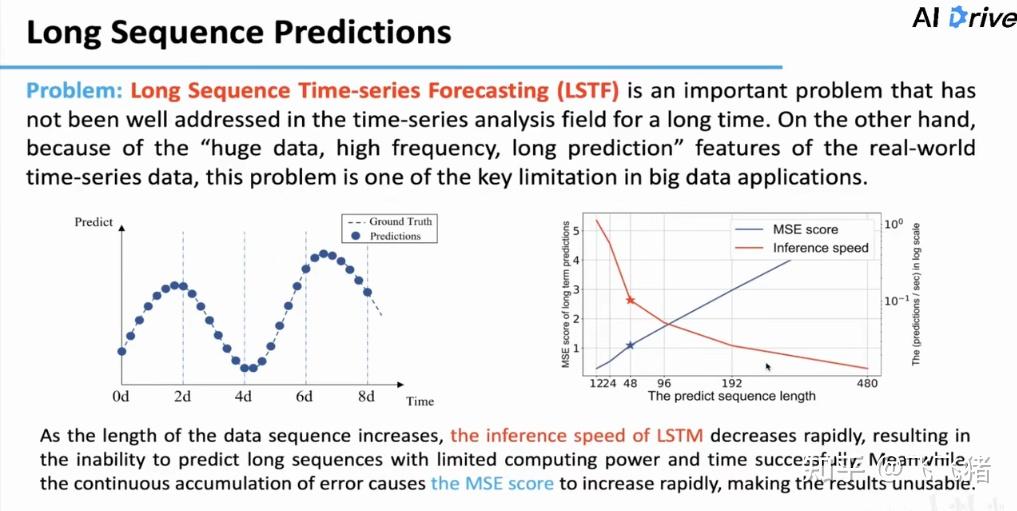
长序列时间序列预测(LSTF)因为数据量大,预测频率高,预测时期长等特点难度是十分大的,这里作者用LSTM(RNN的一种)模型做了算例,发现不仅预测时间随着预测长度的增加大幅增大(注意右边是指数坐标轴),预测误差(MSE)也因为误差累计越来越大。
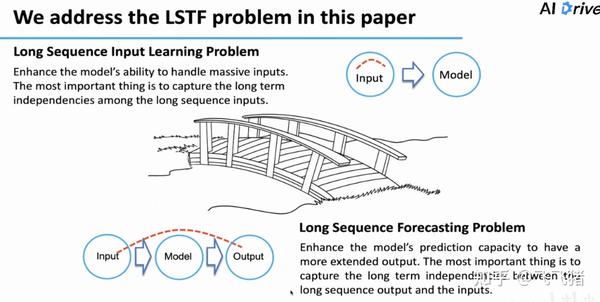
机器学习领域还有另外一个很重要的预测问题,是长序列输入学习(LSIL),这类问题的特点是输入非常长,有可能是一本书的全部内容,要求输出文本总结。


这里这种突出两类问题的区别:LSIL问题着重于对输入的准确表征,而LSTF问题除了对于输入要表征准确外,更看重output的准确性以及output与input间的长期依赖关系。

为什么是attention?
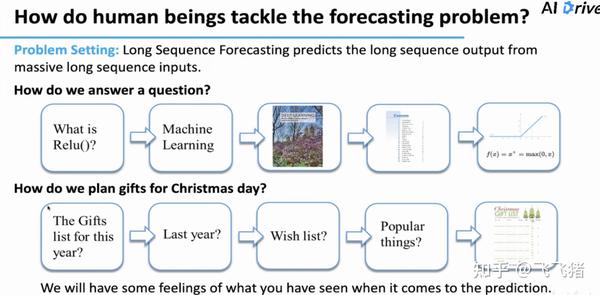
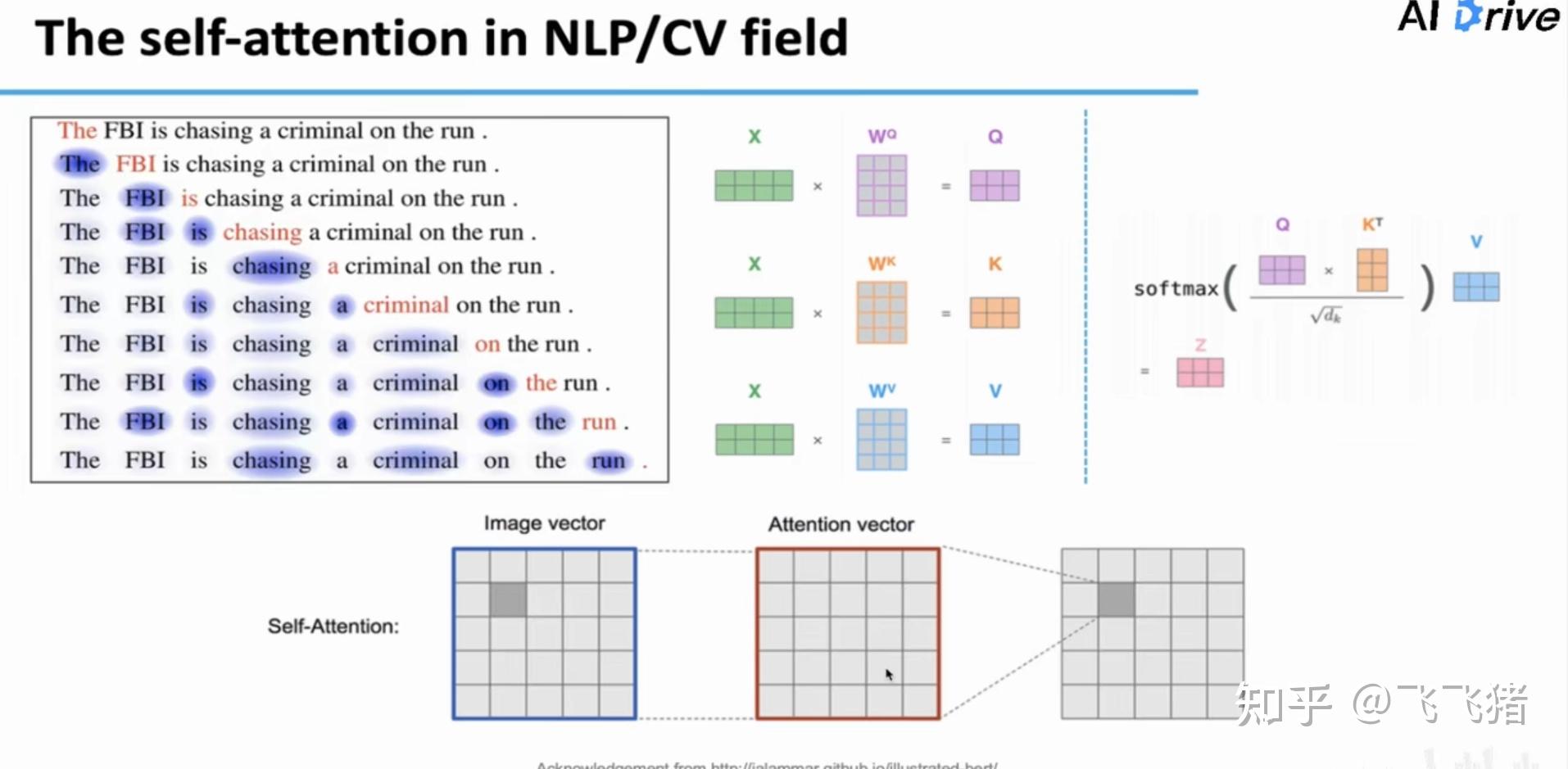
在生活中,但我们人类遇到问题需要预测答案时,在思考的过程中,往往会形成注意力。

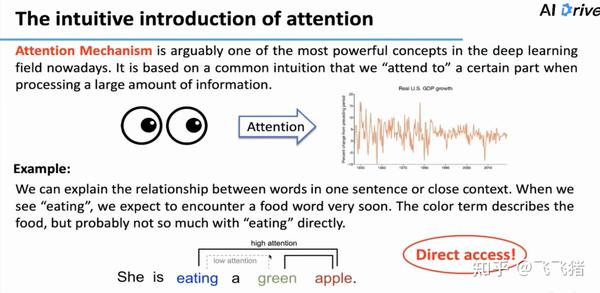
接下来,作者简单介绍了注意力机制,不知道的同学可以看下我之前发的关于attention的详解,这里作者强调了注意力很适合LSTF任务的一个特点,不管输入相隔距离有多远,彼此之间都是直接连接(direct access):
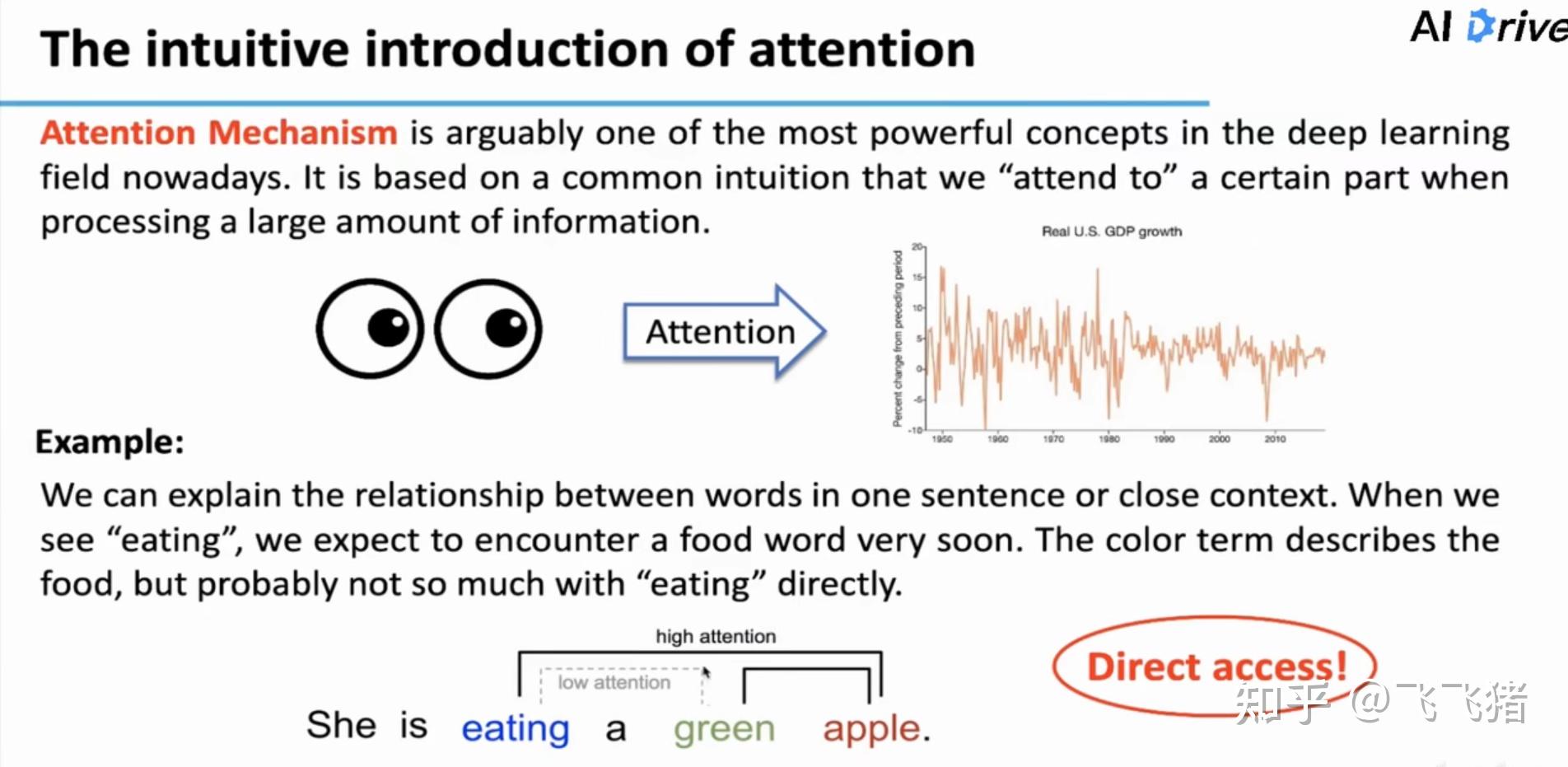
在文本转录任务中,transformer模型利用自注意力机制已经取得了非常好的效果。

现有挑战
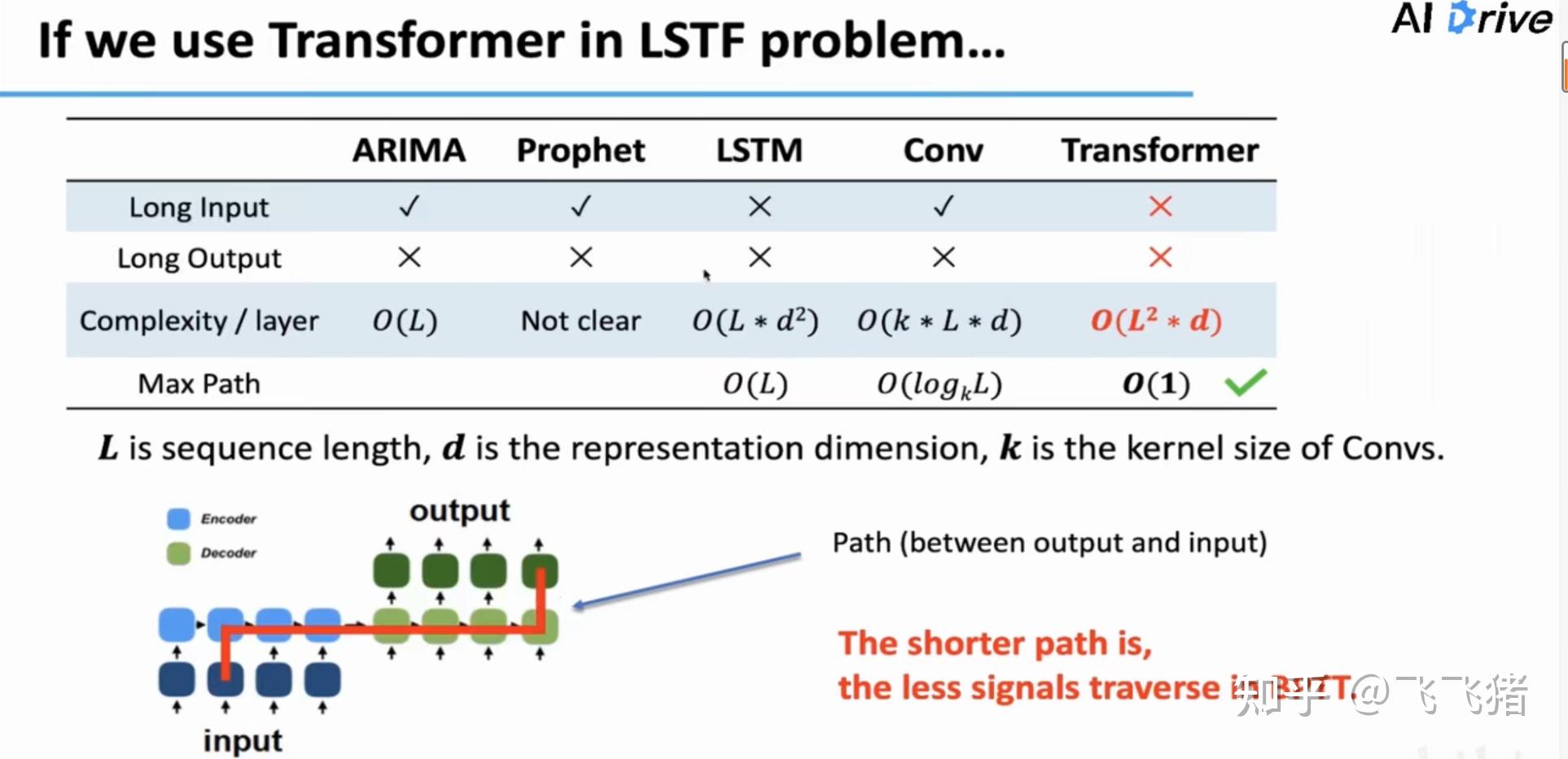
一般我们认为,在模型中,预测与输入在时间维度上离得越近,越有利于梯度信息的传递,如图所示,transformer和一些常见的time-series forecasting模型相比,是有优势的。但是transformer本身用作LSTF任务是存在问题的:
不支持长序列input;
不支持长序列output;
由于其要计算每两个点间的注意力,所以每一个注意力层的计算复杂度都是O(L*2*d),所以直接用它来处理超长序列输入时不现实的。

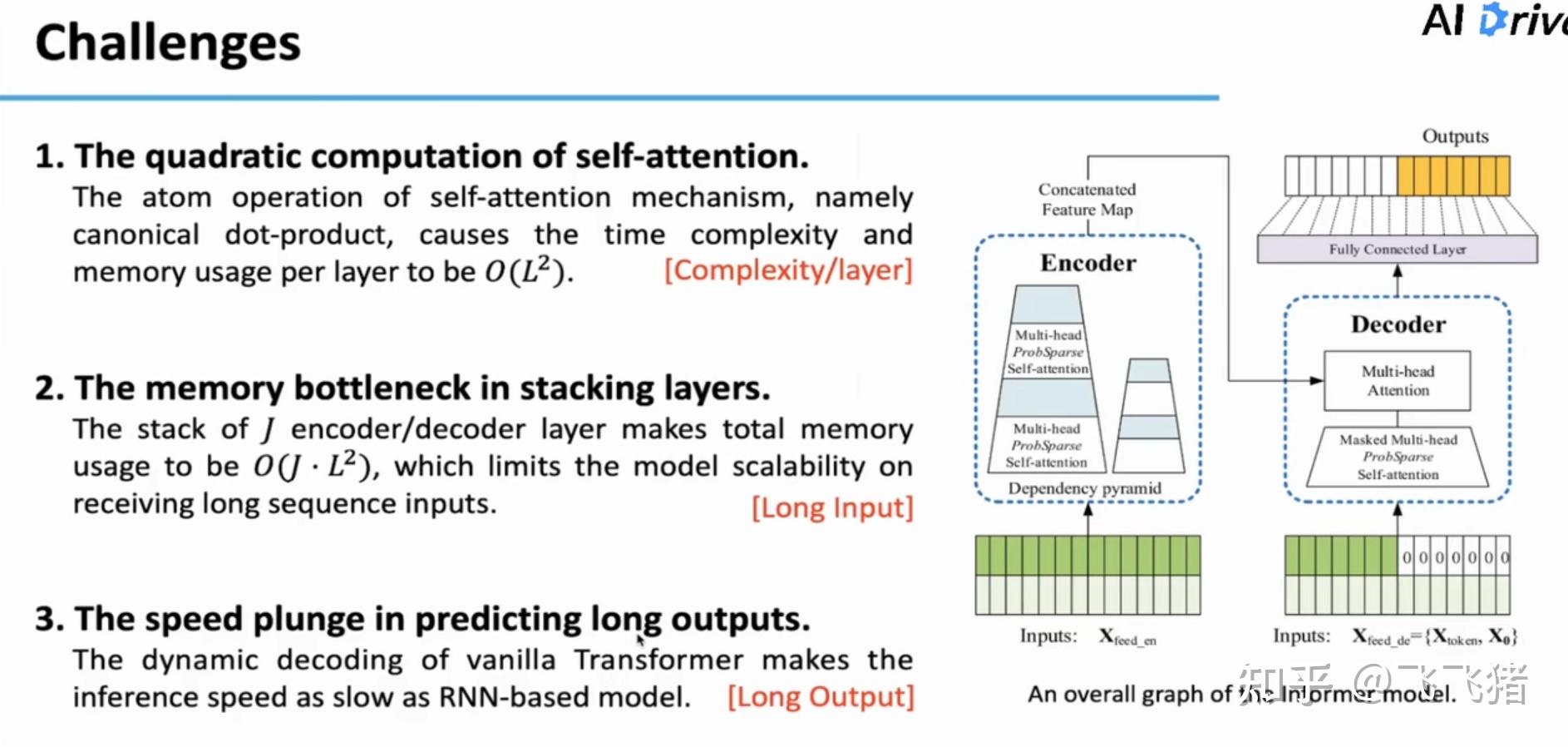
这三大问题对应的具体原因如下:
--------------------------------------------------------------------------------------------------------------
自注意力中的原子机制(最核心的运算单元)是点积操作,每一层会产生 O(L^{2}) 的内存使用量(memory usage);
--------------------------------------------------------------------------------------------------------------
通常,transformer要堆叠很多( J 层)的encoder和decoder层,这样会使内存使用总量来到 O(J*L^2) ,因此模型不能接受过长的输入;
--------------------------------------------------------------------------------------------------------------
原始transformer的 动态编码机制(递归)使得它的inference过程和RNN-based模型一样慢,因此,不支持生成很长的输出。
--------------------------------------------------------------------------------------------------------------
本文核心方法
首先,作者给出的是关于如何解决问题1的思路。在自注意力机制运行时,让我们看看QK点积经过可视化的样子。现有一些方法例如:稀疏transformer、指数稀疏transformer或者重启点+指数稀疏transformer都是一些启发式(人为规定)方法,不能自适应的减少计算复杂度。


通过可视化结果可以看到,在QK进行完点积运算以及softmax后,只有一少部分的值是有效的,他们值的分布类似一个长长的拖尾。


在一个训练好的模型中,我们将查询矩阵Q拿出来,可以发现Q大致可以分成两类,一类是‘’活跃的‘’,一类是‘’慵懒的‘’。


那该如何定量的去评价Q到底是lazy还是active呢?作者通过计算KL散度推导出一个有关查询向量q的稀疏值的指标 M(q_{i},K) ,这个值越大,意味着某个q的分布和均匀分布长的越不像,越有可能是一个‘’活跃的‘’q。


因此作者提出了ProbSparse Self-attention机制,让每个k只注意u个q(把原先的Q变成了一个稀疏矩阵)。u的计算方式作者在论文中有详细的给出。


但是通过这种方式,我们在选出top u个q的时候,还是需要遍历整个q,计算复杂度仍然是 O(L^2) 。而且 M(q_{i},K) 中有一项 ln 项,这一项在计算时因为截断误差的原因会出现计算不稳定的问题。为了解决计算稳定性的问题,我们将 ln 项替换成 max 项(如图)。
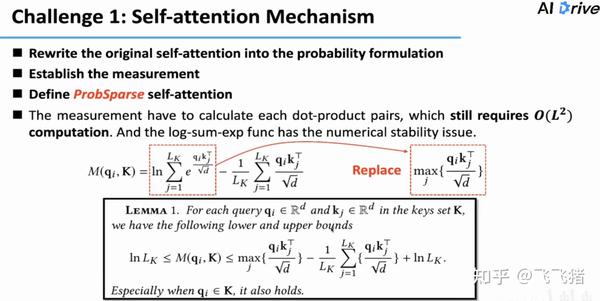

其实,通过实验发现,我们没有必要在计算时用到全部L个q,而是只需要采样 logL 个q就足以拟合原有的分布(后续作者上线了具体的证明过程)。计算复杂度现在就变成了 O(L*logL) ,意味着第一个challenge解决了。


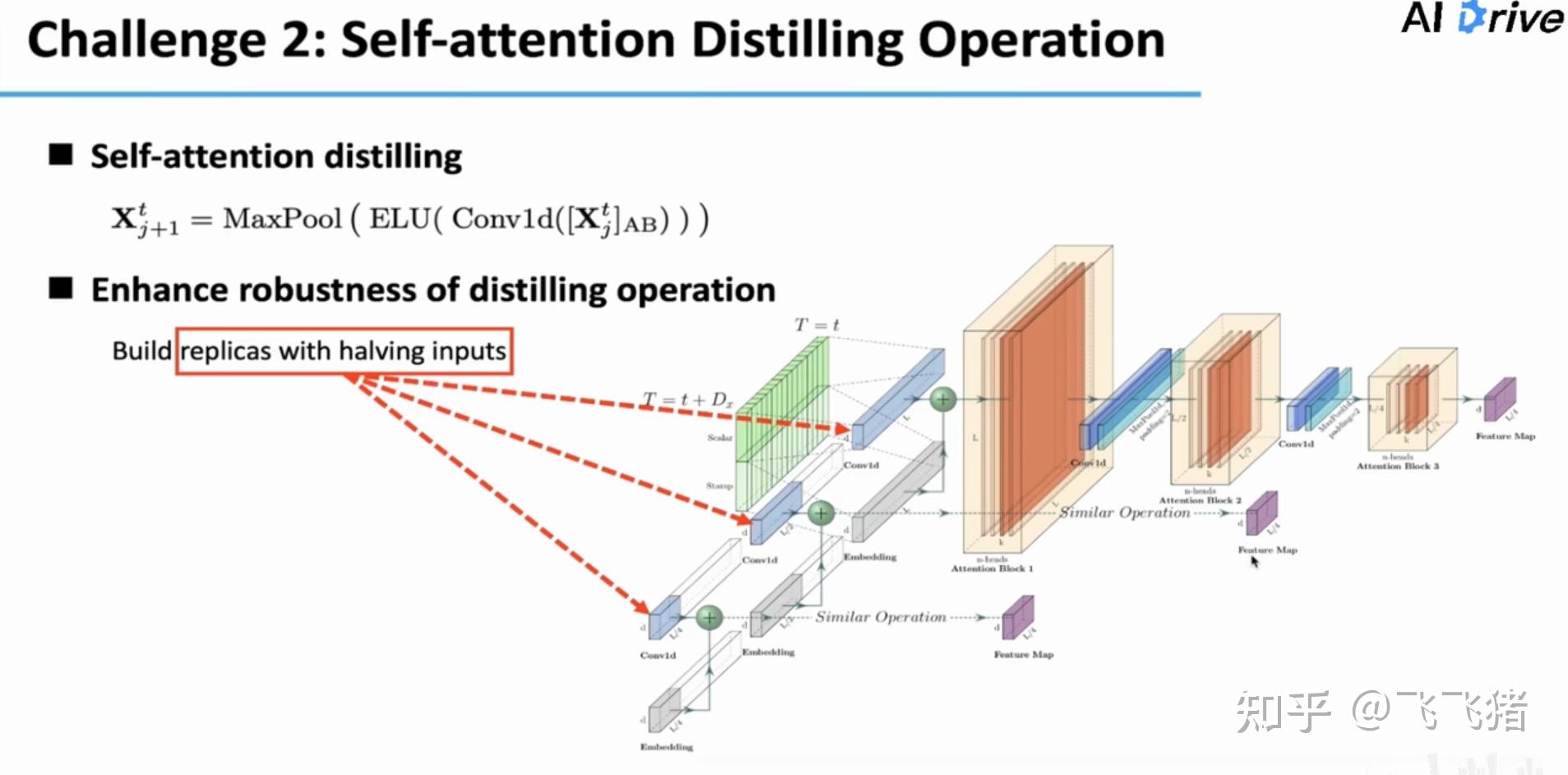
让feature map逐层减小,具体做法是:在每个AB(attention block)后加一个conv1D层,将原先大小为L*L的feature map变成L/2 * L/2的大小,再通过同样的方法,最终让其变成L/4 * L/4的大小。同时,为了增强模型的鲁棒性,并列的复制了模型的结构,只不过输入的长度用的分别是原始输入的1/2和1/4。

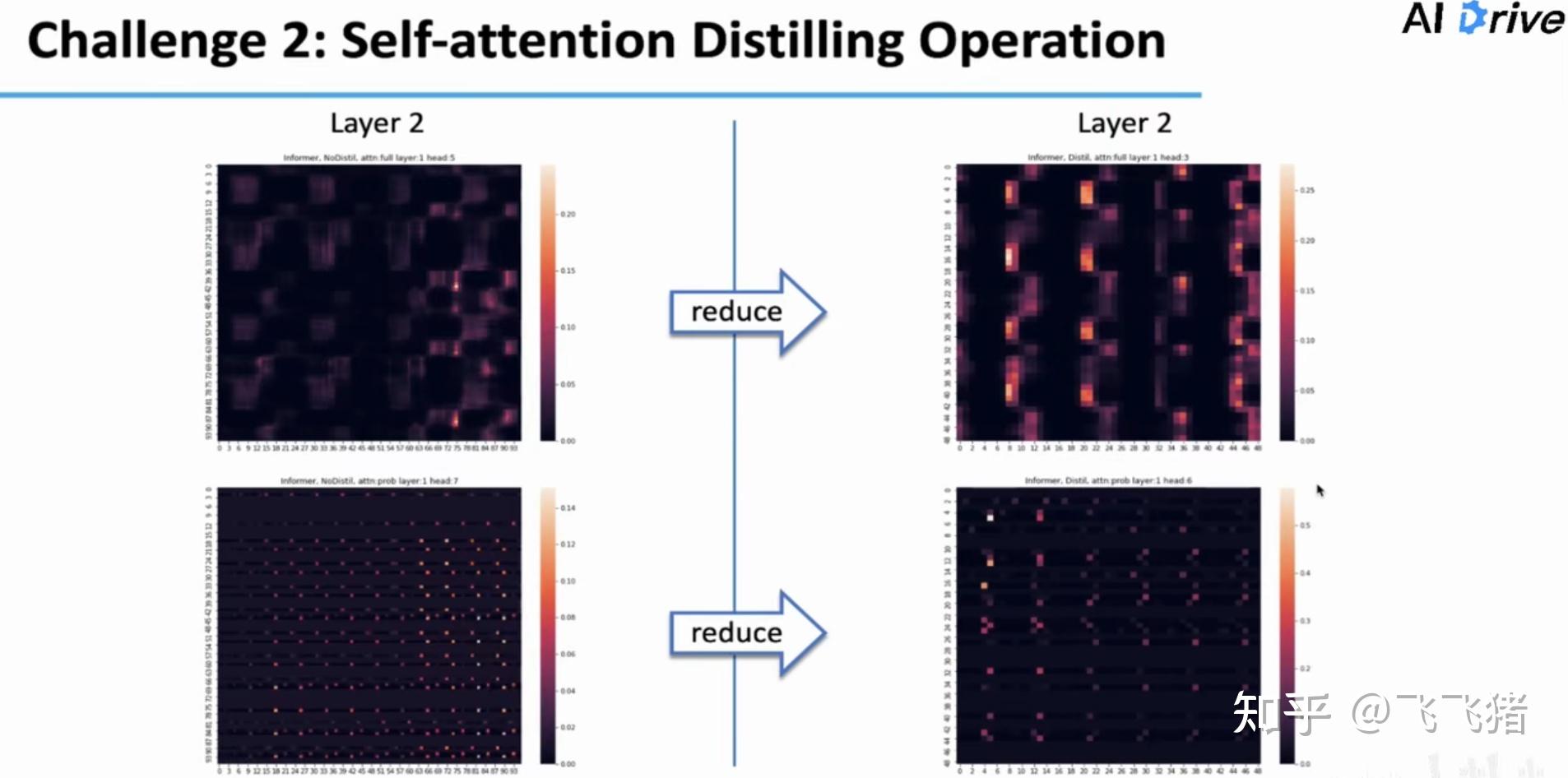
这里文章对上面提到的两种方法的效果进行了可视化分析,右边是加了distilling的,下面是加了probsparse的。可以看到,加了distilling的方法,在保留原始patten的同时,局部特征更亮;加了probsparse的方法,主导性特征保留的同时,对周期性特征的捕捉更强了,当然从图中看暗的地方也更多(证明稀疏性)。

这样long input的问题也解决了,总的计算复杂度大幅下降了。


最后一个挑战,是关于原始版本的transformer的decoder部分在inference时是遵循one time-step by one time-step的形式,也就是输出一个一个的往外蹦,这样在输出很长时是十分消耗计算资源的。在NLP领域,解决这类问题的常见做法是使用start token方法,文章里是对该方法应用的拓展。Informer的decoder部分会一次性地输出全部output,其使用输入序列中靠近预测时间的一段作为decoder的输入。


至此,三个难题已经得到了解决。下面是模型的细节。
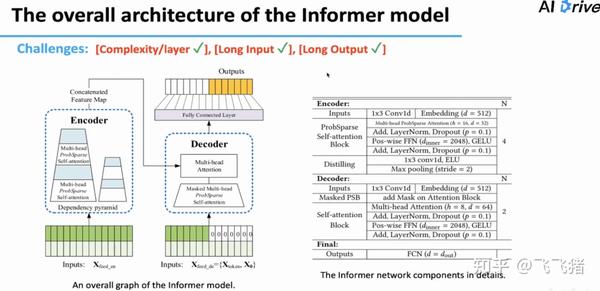

实验
数据集:
ETT(电力变压器)
ECL(电力负荷)
Weather(天气)
对比模型:
ARIMA,DeepAR,Prophet,LSTMa,LSTnet (传统时序预测模型)
vanilla Transformer, Reformer, LogSparse Transformer (transformer-based)
模型衡量标准:
MAE
MSE
平台:
单块Nvidia V100


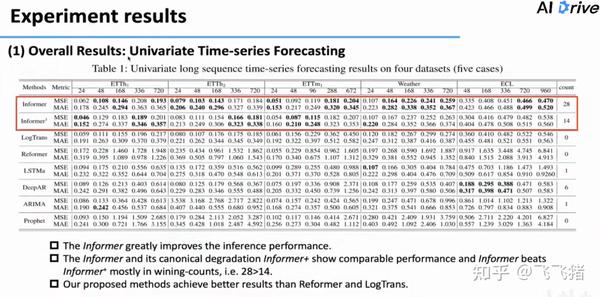
单变量时序预测
表格中的最后一列count表示模型在各组实验中取得最好成绩的次数。可以看到Informer的表现很不错。在预测长度增长时,误差也没有陡增。而且比起Informer+效果更好,证明了ProbSparse attention的有效性。

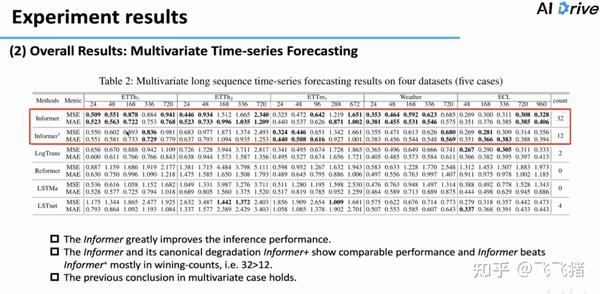
多变量时序预测

不同粒度的数据集上


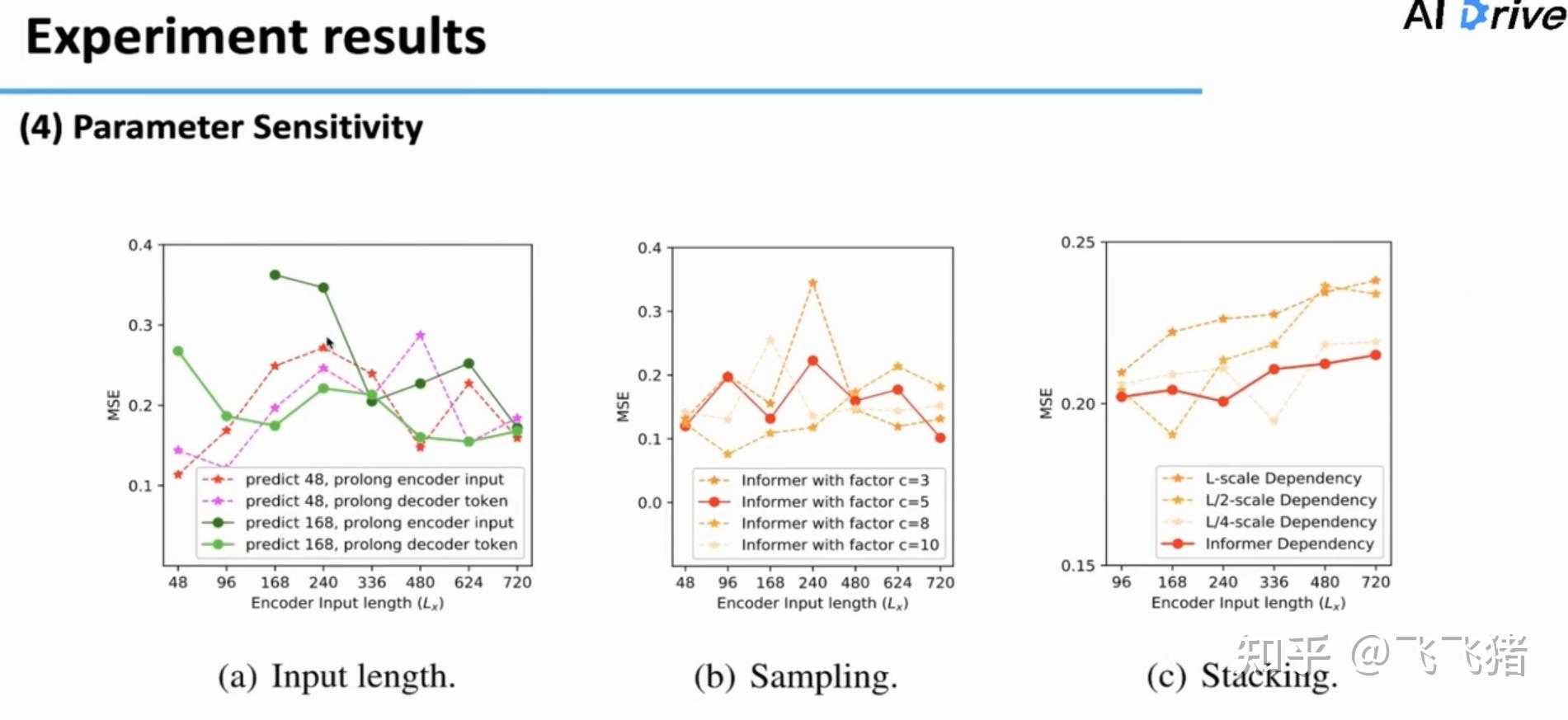
下面是有关模型的参数敏感性分析:
在预测长度为48也就是预测短序列时,随着输入长度增长,一开始MSE有所提升,但后来MSE开始下降,证明增加序列的长度中应该包含部分新信息,更长的decoder的token也证明对预测性能有一定帮助;对于预测长度168的例子来说,更长的encoder input和更长的decoder token对于预测也有帮助。
c是有关于计算Probsparse中top u的采样参数,当c=5时,模型比较稳定。
关于stacking部分ppt中没有给太详细的解释,想了解的同学可以去文章里细看。

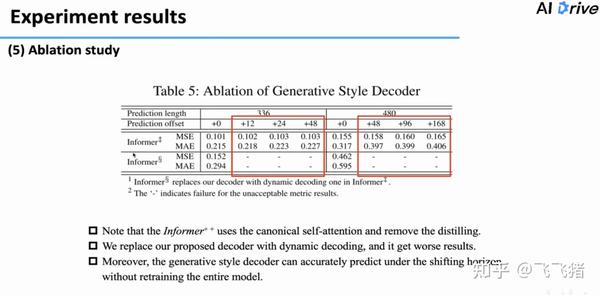
下面是消融实验,验证提出方法的有效性。
可以看到,使用ProbSparse self-attention的模型能handle更长的输入序列,而且在相同长度的序列上也有更好的效果。


比较奇怪的是,移除self-attention distilling模型会有更好的效果,但是模型失去了在更长的输入上进行预测的能力。


最后的消融实验是把decoder换成了原始的dynamic decoding,可以看到,预测结果大幅下降。

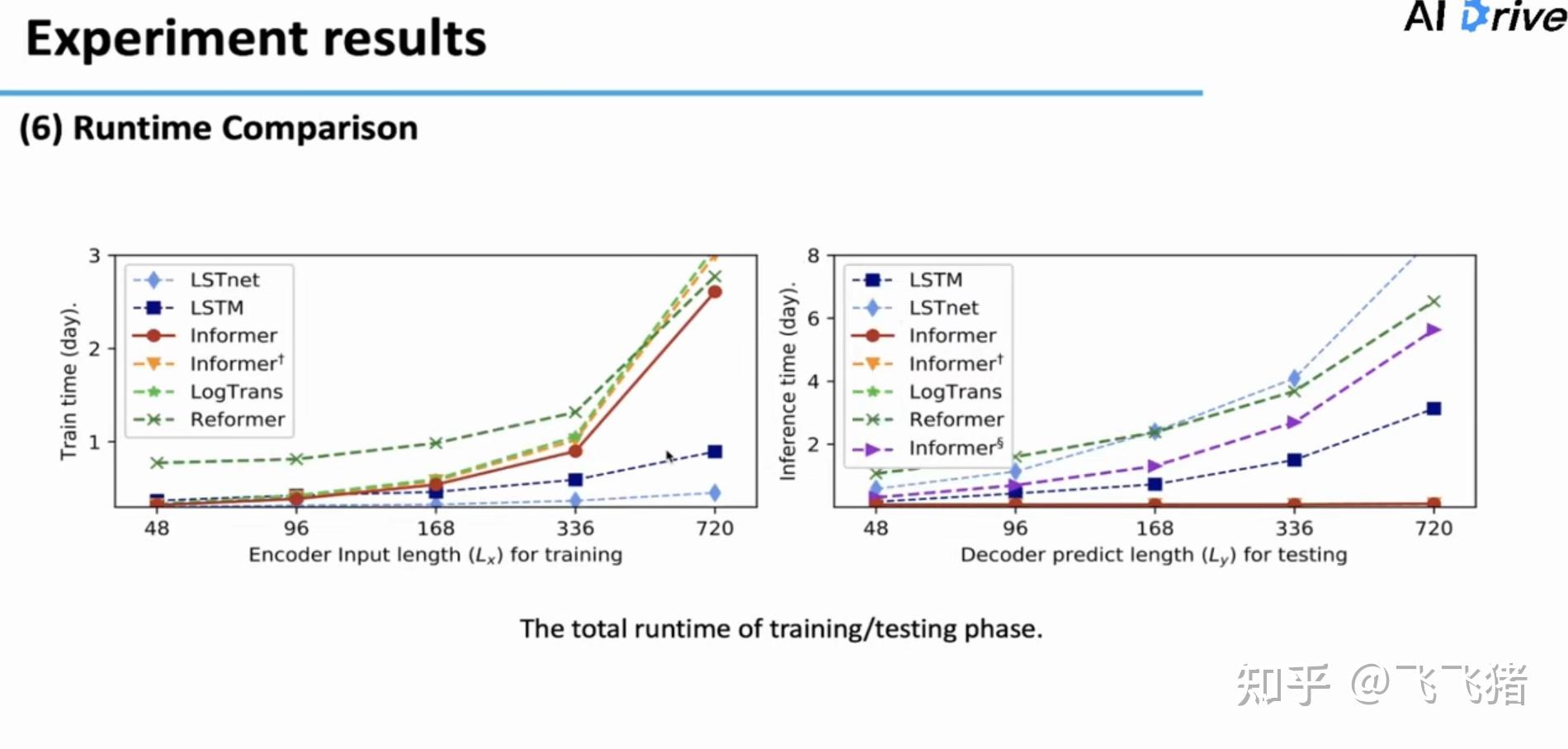
对于减轻计算资源的实验。在训练中,领先所有transformer-based模型;在预测中,领先所有dynamic decording模型。

总结

