
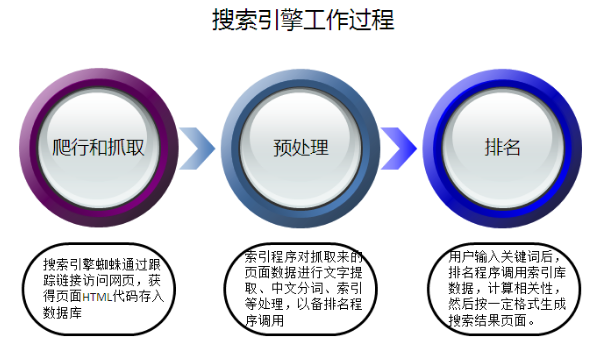
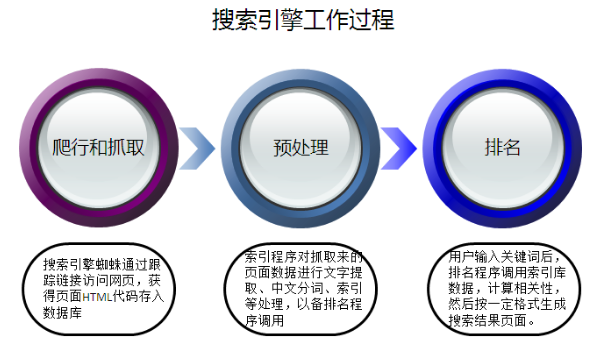
SEO基础入门之搜索引擎工作原理

搜索引擎的工作原理可以分为3个部分:
第一部分:搜索引擎派遣蜘蛛在互联网中发现、搜集网页信息,也称为“抓取”。
搜索引擎的抓取程序Spider会顺着网页中的超链接,从网站首页爬到网站的其他页面,或者从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页。被抓取的网页被称之为“快照”。由于互联网中,超链接就是各个页面之间的联系,理论上,搜索引擎蜘蛛能够搜集到绝大多数的网页。(但是由于一些操作失误或者其他原因,总会有一些网页没有被蜘蛛抓取到,做SEO就要让蜘蛛抓取到我们网站中更多的网页。)
搜索引擎蜘蛛的工作原理有两个方面:
①深度优先。
深度优先就是指蜘蛛到达一个页面后,发现一个锚文本链接,就是爬进去另个一页面,然后又在另一个页面发现另一个锚文本链接,接着往里面爬,直到最后爬完这个网站。如图:
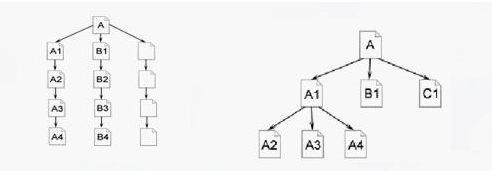
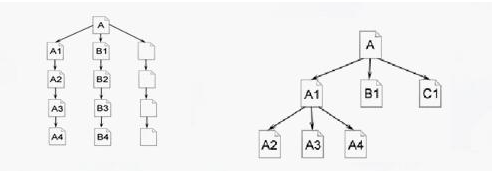
②广度优先。
广度优先就是蜘蛛到达一个页面后,发现锚文本不是直接进去,而是把整个页面所有都爬行完毕,再一起进入所有锚文本的另一个页面,直到整个网站爬行完毕。
不同的搜索引擎是有不同的蜘蛛的:
- 百度蜘蛛:Baiduspider,包括Baiduspider-image(抓取图片)、Baiduspider-mobile(抓取wap)Baiduspider-video(抓取视频)、Baiduspider-news(抓取新闻)
- 谷歌蜘蛛:Googlebot
- 360蜘蛛:360Spider
- 搜狗蜘蛛:Sogou News Spider。
- 搜狗蜘蛛还包括如下这些:Sogou web spider、Sogou inst spider、Sogou spider2、Sogou blog、Sogou News Spider、Sogou Orion spider
- SOSO蜘蛛:Sosospider
- 雅虎蜘蛛:Yahoo! Slurp China
- 有道蜘蛛:YoudaoBot或者YodaoBot
- MSN蜘蛛:msnbot-media
- 必应蜘蛛:bingbot。
- 一搜蜘蛛:YisouSpider。
- Alexa蜘蛛:ia_archiver。
- 宜搜蜘蛛:EasouSpider。
- 即刻蜘蛛:JikeSpider。


第二部分:处理网页,对信息进行提取和组织建立索引库,把垃圾内容从搜索引擎数据库中剔除出去。
搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引。其他还包括去除重复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。在这过程中,搜索引擎就会把低质量的内容从自身的数据库中清除出去,保留高质量的内容。
在这个环节当中,作为网站管理者的SEOer,要做的就是做好网站的内容,提高网站内容的质量。

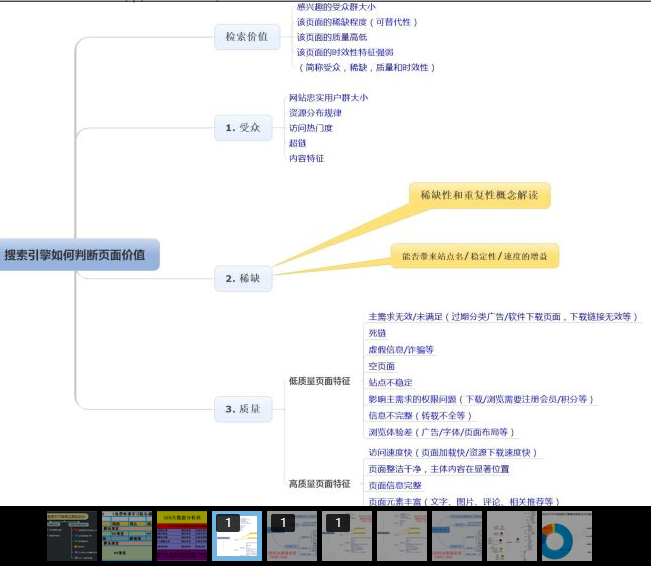
第三部分:提供检索服务,展示网站排名。
当用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。
注意:仅仅有蜘蛛抓取网站页面是不一定有排名的,还需要经过搜索引擎的审核,即收录到搜索引擎的数据库里边了,才会有展现、有排名的。