一种基于改进Apriori算法找出频繁项集的方法与流程
本发明涉及数据挖掘领域,特别涉及一种基于改进apriori算法找出频繁项集的方法。
背景技术:
目前,在移动终端的应用软件,比如购物应用软件上能够采集到的用户行为数据不断增长,通过分析数据库中这些海量的用户行为数据,获得用户在操作购物应用中潜在的内在联系,这可以为用户推荐产品提供有效参考,不仅能提升用户的购买力和体验性,而且能为公司带来广阔的经济效益。比如,利用数据库中的数据可以分析出,哪些商品可能会被大部分用户在一次购物时同时购买,那么把这些经常被同时购买的商品展示在一起,就能增加这些商品一并销售的几率,另外还可以规划哪些附属商品降价处理,以便刺激跟主体商品的捆绑销售,又或者将某几种可能会被同时购买的商品以套餐的形式推出,提升用户的购买欲望以及增加销售量和减少库存量。
从大量的数据中分析用户的行为并找出隐藏的有用信息,就需要用到数据挖掘。关联规则是利用数据挖掘进行数据分析常用的方法之一。关联规则挖掘最主要的一步是找出频繁项集,特别注意本发明也是围绕得到频繁项集展开。关联规则找出频繁项集的方法是:设定最小支持度minsup,找出数据库中所有大于等于最小支持度的频繁项集,即满足支持度计数support≧minsup的所有项集。实际上,得到的频繁项集中可能有包含与被包含的关系。一般情况下,只需要关注那些得到的最大频繁项集即可。关联规则挖掘中,最经典的是apriori算法,它的目的是发现频繁项集。apriori算法利用了如下属性:如果一个项集是频繁项目集,那么它的非空子集必定是频繁项目集,通过多次扫描数据库,迭代循环使项集的长度不断增长,来逐步发现频繁项集,直到不能产生新的频繁项集(非空集合)时为止。
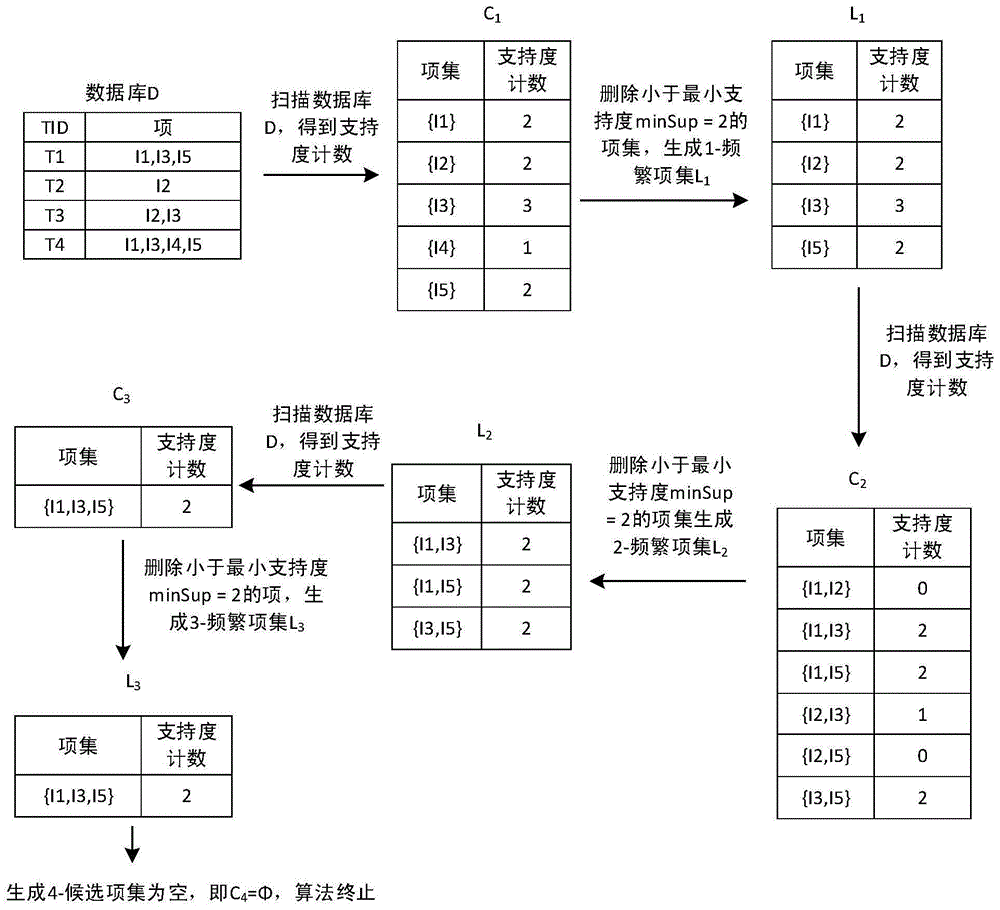
为了更好的理解传统的apriori算法的原理,接下来以一个实例来说明apriori算法的过程。这里要特别说明,实例只是为了说明算法原理,因此这个例子中数据库里的总数据量少,只有四个事务记录,但是实际情况中数据库里面的数据远不止这些,数据非常庞大。给定一个数据库d,里面是采集到的所有用户在购物应用中的行为,设定最小支持度minsup=2,算法执行过程见图1。其中,tid标记每一个不同的用户,项集里的每一条数据表示每一个用户购买的商品,即i1、i2、i3、i4、i5等对应各类商品,比如,i1是饼干、i2是可乐、i3是口香糖等购物应用中在售的任意商品。图中l表示频繁项集,c代表候选项集。
apriori算法实例运行过程步骤如下:
(1)1维频繁项集l1生成
首先扫描数据库d,对每个候选项进行支持度计数得到1-候选项集c1,可以看出各项集与支持度计数的关系是:{i1}:2、{i2}:2、{i3}:3、{i4}:1、{i5}:2。将每一个项集的支持度计数与最小支持度minsup=2进行比较,删除支持度计数<2的项集{i4},得到1-频繁项集l1。
(2)2维频繁项集l2生成
由l1产生2-候选项集c2,再次扫描数据库d,得到各项集与支持度计数的关系是:{i1,i2}:0、{i1i3}:2、{i1i5}:2、{i2i3}:1、{i2i5}:0、{i3i5}:2。同上一个步骤,将每一个项集的支持度计数与最小支持度minsup=2进行比较,删除支持度计数<2的项集{i1,i2}、{i2,i3}和{i2,i5},最终得到2-频繁项集l2。
(3)3维频繁项集l3生成
再由l2生成3-候选项集c3,又一次扫描数据库d,得到项集与支持度计数的关系是:{i1i3i5}:2。这里没有支持度计数<2的项集,最终得到3-频繁项集l3。
(4)4维频繁项集l4生成
由于l3中只有一项元素,不可能再次生成4-候选项集,即c4=φ,循环结束,算法终止。
从上述传统apriori算法流程可以看出,它存在两个弊端:
1、多次扫描数据库,i/o开销大,效率低
在apriori算法中每计算一次项集的支持度计数,就需要全扫描一次数据库,图一实例为了说明原理,事务数量少,只有四条,但是在实际情况下数据库都非常庞大,对数据库的多次扫描会造成很大的i/o负载,导致算法的效率低下。
2、会产生庞大的候选项集,并呈现组合式增长
产生庞大候选项集的主要原因是,数据库里面的事务非常多,每次产生候选项集时组合就非常庞大,而且没有通过一些规则来排除不满足条件的组合元素。
技术实现要素:
本发明要解决的技术问题是:提供一种基于改进apriori算法找出频繁项集的方法,用以解决apriori算法多次扫描数据库导致i/o开销大、效率低、以及产生大量候选项集增加了复杂度。
为解决上述问题,本发明采用的技术方案是:一种基于改进apriori算法找出频繁项集的方法,包括如下步骤:
步骤1:扫描数据库,将数据库映射成布尔矩阵,并对布尔矩阵中的行向量和列向量中1的个数分别计数,得到布尔矩阵的频度;
步骤2:删除布尔矩阵列向量频度小于最小支持度的列,得到1-频繁项集;
步骤3:删除布尔矩阵列向量频度小于最小支持度的列,同时删除矩阵行向量频度小于频繁项集维数k的行,其中k≥2,生成新的布尔矩阵,新的布尔矩阵记为k维布尔矩阵;
步骤4:扫描k维布尔矩阵对应的列,对矩阵的第1,2,…,k列向量进行按位“与操作”,然后对向量运算后的结果中的1计数,得到k维布尔矩阵的频度;
步骤5:删除k维布尔矩阵列向量频度小于最小支持度的列,得到k-频繁项集;
步骤6:令k=k+1,并返回步骤3,重复步骤3-5,不断压缩布尔矩阵,直到下一个频繁项集为空。
进一步的,布尔矩阵中,行代表事务,列代表数据项。
本发明的有益效果是:
附图说明
图1是现有apriori算法流程图。
图2是本发明改进算法流程图。
具体实施方式
本发明针对apriori算法多次扫描数据库导致i/o开销大和效率低、以及产生大量候选项集增加了复杂度等缺陷,提出了一种改进apriori算法找出频繁项集的方法,克服了上述apriori算法的不足,它在找出频繁项集的过程中,只扫描数据库一次,不需要生成候选项集,且内存占用空间小。
改进apriori算法的具体技术方案如下:
(1)只扫描数据库d一次,将数据库映射成布尔矩阵,并对布尔矩阵中的行向量和列向量中1的个数分别计数。矩阵中行代表事务,列代表数据项,通过逐行扫描相应的列就能得到项的频度。由于事务名称一般是由文字组成,将事务数据转换为布尔矩阵,就是将文字转化成了数值,而且是数据存储中最小的布尔型,因此数据库存储占用空间小,另外在生成候选项集时也能减少对内存的占用,从而提高了算法效率。
(2)在布尔矩阵中,若列向量中1的个数小于最小支持度minsup,则可删除此列。由于当列向量中1的个数小于最小支持度minsup时,那么该列为非频繁项集,就与产生2-频繁项集无关,因此可删除该列。
(3)在布尔矩阵中,若行向量中1的个数小于k,则可删除此行,其中k是频繁项集的维数。由于当行向量中1的个数小于k时,此行与产生k-频繁项集无关,便可删除,因此删除行向量计数小于k的事务项,保留1的个数大于等于k的事务项。
(4)在求k(k≥2)维项集的频度时,扫描布尔矩阵对应的列,求k-项集{i1,i2,…,ik}的频度,只需对矩阵的第1,2,…,k列向量进行按位“与操作”,然后对向量运算后的结果中的1计数,如果大于等于最小支持度minsup,则为k-频繁项集的子集,如果小于则不为频繁项集。扫描完布尔矩阵,保留下来的子集即为所求频繁k-项集。
(5)重复步骤(2)和(3),不断压缩矩阵,一方面可以降低矩阵的大小,另一方面可以提高算法的运行效率。然后再执行步骤(4),直到下一个频繁项集为空,算法终止。
归纳起来,本发明的算法实施流程可如下:
步骤1:扫描数据库,将数据库映射成布尔矩阵,并对布尔矩阵中的行向量和列向量中1的个数分别计数,得到布尔矩阵的频度;
步骤2:删除布尔矩阵列向量频度小于最小支持度的列,得到1-频繁项集;
步骤3:删除布尔矩阵列向量频度小于最小支持度的列,同时删除矩阵行向量频度小于频繁项集维数k的行,其中k≥2,生成新的布尔矩阵,新的布尔矩阵记为k维布尔矩阵;
步骤4:扫描k维布尔矩阵对应的列,对矩阵的第1,2,…,k列向量进行按位“与操作”,然后对向量运算后的结果中的1计数,得到k维布尔矩阵的频度;
步骤5:删除k维布尔矩阵列向量频度小于最小支持度的列,得到k-频繁项集;
步骤6:令k=k+1,并返回步骤3,重复步骤3-5,不断压缩布尔矩阵,直到下一个频繁项集为空。
实施例
图2是实施例的改进算法流程图,采用跟传统apriori算法一样的数据库即图一中的d,改进算法包括的步骤如下:
(1)1维频繁项集l1生成
首先扫描数据库d,将数据库映射成布尔矩阵,并对布尔矩阵中的行向量和列向量中1的个数分别计数。删除矩阵列向量计数小于最小支持度minsup=2的项目列i4,保留下来的项目列构成下次扫描的矩阵,根据列向量计数即可得1-频繁项集l1。
(2)2维频繁项集l2生成
扫描布尔矩阵对应的2-项集列,对矩阵的第1、2、3、5列向量进行按位“与操作”,然后对向量运算后的结果中的1计数,求出2-项集的频度,将大于等于最小支持度minsup=2的子集保留即可得2-频繁项集l2。首先,i2列1的个数小于最小支持度minsup=2,因此删除的列是i2列,然后,t3行1的个数小于3,因此删除的行是t3行,最后生成新的布尔矩阵。
(3)3维频繁项集l3生成
扫描布尔矩阵对应的3-项集列,对矩阵的第1、3、5列向量进行按位“与操作”,然后对向量运算后的结果中的1计数,即可得3-频繁项集l3。由于t1、t4行1的个数小于4,因此删除t1、t4行。
(4)4维频繁项集l4生成
由于在生成l3后矩阵为空,所以不会存在4-频繁项集l4即l4=φ,算法终止。
- 用户群分类方法、装置、设备及...
- 一种基于云平台的上下文感知实...
- 性能分析方法、装置、计算机设...
- 试驾车型推荐方法及装置、计算...
- 自动任务处理方法及装置、计算...
- 管理信息处理任务的有效性的方...
- 一种新型分布式NEWSQL数...
- 数据展示方法、装置、设备及计...
- 一种基于人工智能技术的模型维...
- 诊断报告生成方法、系统、设备...
- 还没有人留言评论。精彩留言会获得点赞!
- 细粒度的基于频繁项集挖掘产生api替换规则的方法
- 频繁序列挖掘方法
- 基于频繁子图挖掘的错误定位方法
- 一种基于频繁模式增长算法的网络攻击路径重构方法
- 一种随机型分布式数据流频繁项集挖掘系统及其方法
- 基于最大频繁项集挖掘的微博炒作群体发现方法
- 基于频繁模式的选择性集成分类方法
- 一种基于图形处理器并行计算的频繁子图挖掘方法
- 基于频繁项集挖掘算法的反规范化策略选择方法
- 基于占有率的模式挖掘的制作方法