一种基于XGBoost的高维数据集自适应特征选择方法与流程
本发明涉及一种高维数据集数据挖掘领域,具体的涉及一种基于xgboost的高维数据集自适应特征选择方法。
背景技术:
特征选择是数据挖掘算法中一个非常关键的步骤,其目的是基于某种规则选择j个特征的子集,使得分类器达到最优性能,其中,j是用户自定义的一个参数。尤其在现实生活中类别不平衡的数据普遍存在,由于传统采样技术和算法层面的方法不足以解决高维的类不平衡问题,而数据集的类别不平衡问题通常都出现在高维数据集上,因此特征选择极为重要。
从另一方面看,多种不同数据的特征联合必然会导致特征集维数大幅增加,而如何有效地从高维特征数据集中提取或选择出最佳的特征子集用于后续地数据分类,得到最佳的分类结果,也是众多研究领域的重点。
技术实现要素:
为了弥补先有技术的不足,本发明构建了一种基于xgboost特征重要性排序算法来评估特征的分类能力,并结合皮尔逊相关系数以及平均中位数(mean-median,mm)算法的特征选择方法计算特征之间的相关程度,设定相关系数阈值,去除特征之间高度相关但分类能力较弱的特征。
为了实现上述目的,设计了三个部分:连续型属性的相关度计算、文本型属性的相关度计算以及高相关性特征子集构建。
其具体的实现方法如下:
所述连续型属性的相关度计算,对于连续型变量,通常采用皮尔逊相关系数计算某两个变量之间的相关性,它是反映两变量相关关系的方向和密切程度的指标。由于特征计算值在一定的区间范围内可以认为是连续的,所以利用皮尔逊相关系数来衡量两个连续型特征之间的相关程度。特征fa、fb的相关系数用rab表示
其中,n表示样本个数。相关系数rab的值域为[-1,1],rab>0表示两变量正相关,rab=0表示两变量不相关,rab<0表示两变量负相关。|rab|的值越接近1,表示两变量的相关程度越高。
所述文本型属性的相关度计算,其具体的计算方法为:
arturj.ferreira等人提出平均中位数(mean-median,mm)算法并应用于高维数据的降维,其方法根据平均值和中间值之间的绝对差来为每个特征分配相关性评分值,可用于选择具有相关性信息的特征。计算公式如式(2)所示。
其中,median(xt)表示特征词t的中间值。
所述的高相关性特征子集构建,其具体的工作为:
首先在每轮确定即将剔除的特征之后,根据该特征的属性计算该剔除特征与当前保留特征集中其他特征的皮尔逊系数或平均中位数(mean-median,mm)得分值的特征选择方法,将所有相关系数的绝对值的均值作为阈值,绝对值大于阈值且在该轮重要性排序中位于后50%的特征,在下一轮中也一并剔除,剩余的保留特征重新进行新一轮的预测和排序,记录每轮迭代过程中的预测分类准确率,并将其作为评价函数值,用于确定预测分类准确率最高的保留特征子集,即为最终特征选择的结果。
本发明的与现有的主流的特征选择算法相比,其优点在于:
对于高维数据集容易造成模型训练过拟合等问题,通过采用xgboost算法统计得出训练样本特征重要性排序,并剔除重要性最末以及相关的冗余特征,多次重复得到最优特征集合。该方法在提高分类效率的情况下,分类精度也有所提高。
附图说明
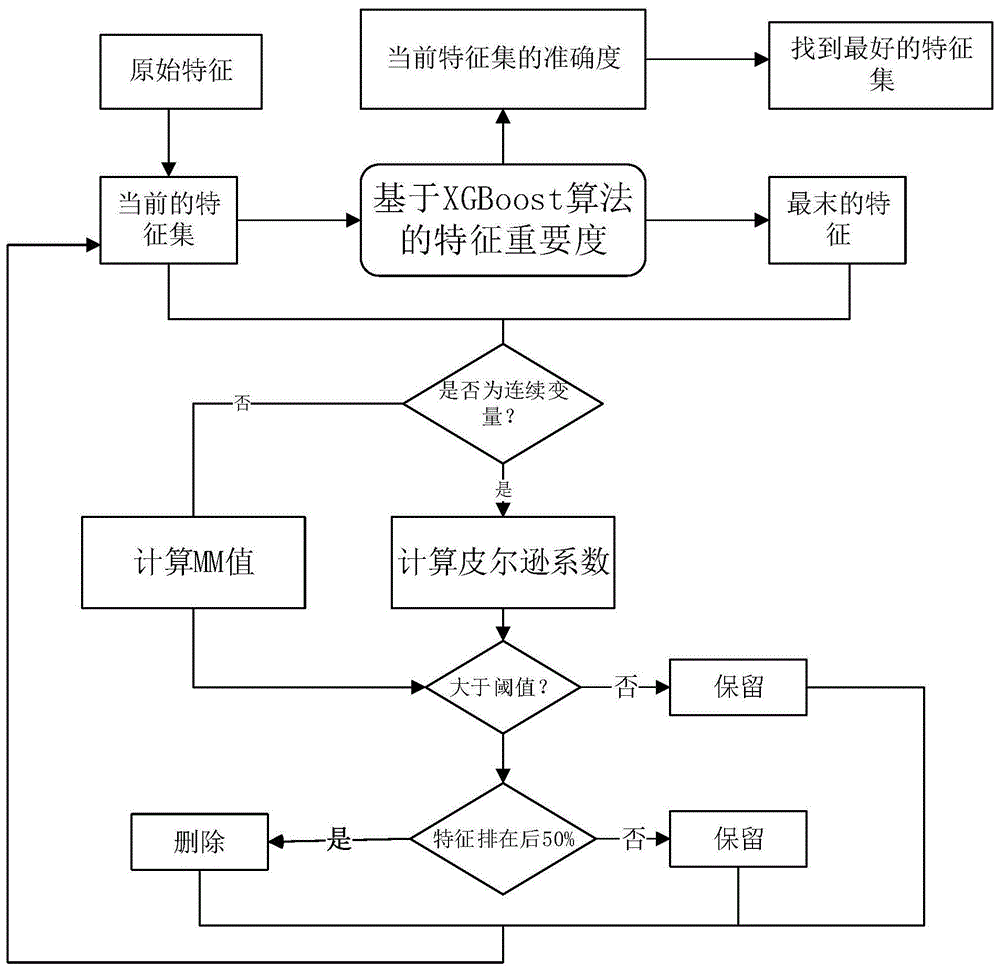
图1是本发明的算法流程图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图说明本发明的具体实施方式。
图1是本发明的算法流程图:
第一步:将所有原始特征组合在一起构成原始特征集合f,利用xgboost特征重要性算法计算f中每个特征的分类重要程度得分,并依据分类重要程度得分从大到小排序。
其中,特征变量m的重要程度指数im可以表示为
变量重要程度指数im能够反映出该变量的分类能力的强弱。将各特征按照其特征变量重要程度指数的高低进行排序,排名靠后的特征分类能力较弱,可以认为该特征对分类贡献较小而予以剔除。
第二步:根据特征分类重要程度得分的高低,取出重要性排序最末位的特征作为待提出特这,表示为t,并将f中的其余特征按照类型分类,选出所有连续型特征组成特征子集f1,所有文本型特征组成特征子集f2;
第三步:判断待剔除特征t的类型,若该特征为连续型特征变量则计算t与特征子集f1中其他所有特征的皮尔逊相关系数并执行第四步;若该特征为文本型特征则计算t与特征子集f2中其他所有特征的mm值并执行第五步;
其中,两个连续型特征fa、fb的相关系数用rab表示
其中,n表示样本个数。相关系数rab的值域为[-1,1],rab>0表示两变量正相关,rab=0表示两变量不相关,rab<0表示两变量负相关。|rab|的值越接近1,表示两变量的相关程度越高。
两个文本型特征之间的相关度计算公式为:
其中,median(xt)表示特征词t的中间值。
第四步:将所有相关系数的绝对值的均值作为阈值i,对于绝对值大于阈值且在该轮重要性排序中位于后50%的特征,在特征子集f1中剔除;
第五步:根据式(3)得到特征的相关性得分值,将所有得分值的均值作为阈值i,并将特征子集f2中得分值大于阈值且在该轮重要性排序中位于后50%的特征剔除;
第六步:合并特征子集f1与f2,得到新的特征集f,对特征集f中的每一个特征都执行第一步到第五步,最终即可得到最优特征集合c。
- 特征场景数据挖掘方法、装置和...
- 动态场景标注数据挖掘方法、装...
- 数据检索方法、数据检索装置、...
- 数据共享方法及装置、电子设备...
- 配餐方法、装置、电子设备及计...
- 一种电子设备的关机定位方法及...
- 一种数据库读取数据方法、装置...
- 数据处理方法、装置、系统及N...
- 基于数据缓存的查询方法、终端...
- 一种数据处理方法、装置和计算...
- 还没有人留言评论。精彩留言会获得点赞!
- 基于遗传算法从大规模高维数据中检测离群数据的方法
- 一种非规则流中高维数据流的gpu处理方法
- 一种基于高维数据过滤器的近似成员查询方法
- 采集的高维数据转换为低维数据的系统及方法
- 增量式的高维数据转换为低维数据的系统及方法
- 经高维数据分类的识别的制作方法
- 用于处理高维数据的系统和方法
- 一种高维数据管理及关联数据动态对比显示方法
- 用于内插高维、非线性数据的设备、系统和方法
- 一种分布式系统中高维流量数据变化点检测方法
- 数据降维方法及基于数据降维方法的人脸识别方法
- 一种高维空间数据的安全查询方法、装置及系统的制作方法
- 一种基于角度的高维数据离群检测方法
- 从高维非对称数据中提取分类信息的方法
- 例外点抑制的数据判别降维方法
- 一种人脑组织高维可视化方法
- 一种高维指数信号数据补全方法
- 一种大规模高维数据中离群数据的检测方法
- 一种降维映射的大数据可视化方法
- 一种基于主成分分析的病理图像视觉效果改善方法