
人工智能之强化学习-给机器一块糖 让她变得更聪明
2016年3月有件大事,人工智能围棋机器人AlphaGo与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜,AlphaGo一举成名,人工智能吸粉无数。
接下来一年,AlphaGo版本机器人更是在围棋界所向披靡,2017年5月,在中国乌镇围棋峰会上,AlphaGo Master与排名世界第一的世界围棋冠军柯洁对战,以3比0的总比分获胜。围棋界公认阿尔法围棋的棋力已经超过人类职业围棋顶尖水平。
一年后,AlphaGo的研发团队Deepmind又推出了最强版的围棋机器人AlphaGo Zero。AlphaGo Zero是自学能力超强的机器人,经过短短3天的自我训练,自我对弈的棋局数量为490万盘,就强势打败了此前战胜李世石的旧版AlphaGo。然后继续自我训练,40天后出关,击败了打败柯洁的AlphaGo Master。AlphaGo Zero的一大核心就是强化学习。
最近很多正在学习 flare老师的实战课程的小伙伴都对强化学习感兴趣,那flare老师今天就来和大家说说听上去高大上的强化学习,也就是reinforcement learning。
1、基本概念
强化学习,根据机器行动给予奖励或惩罚,让机器对外部环境做出反应自己决定接下来做什么:
做对了,奖励一下,给颗糖;
做错了,惩罚一下,拿走糖。
嗯,核心就这么简单。我们来看个简单的例子:小朋友学走路
以下是孩子学习走路时将采取的步骤:
- 观察大人的走路方式:两条腿走路,一次走一步。掌握了这个概念,他/她可以尝试这么去重复步骤。
- 但是很快他/她就会明白,走路之前必须站起来!这是尝试走路时面临的挑战。因此,他/她试图起身,蹒跚和滑倒,但仍然决定要起身。
- 接下来还有另一个挑战要应对。站起来很容易,但保持静止 是另外一个任务!抓住空气,寻找支持,他/她设法保持站立。
- 现在,孩子的真正任务是开始走路。但是说起来比实际做起来容易。有很多事情要记住,例如平衡体重,决定下一步放哪只脚以及在哪里放脚。
- 听起来像是一项艰巨的任务,对不对?起身并开始行走实际上有点挑战,但是我们已经习惯了它,以至于我们不会对任务感到困惑。但是,对一个小孩来说这就很难了。
让我们对上面的示例进行形式化,该示例的“问题陈述”是走路,为了能成功平稳的行走,他/她尝试从一种状态(即他/她采取的每个步骤)发展到另一种状态。当孩子完成任务的子模块时(即走几步),他会得到奖励(比如说糖果),而当他/她不能走路时,他不会得到任何糖果 (也就是负奖励)。这是对强化学习问题的简化描述。

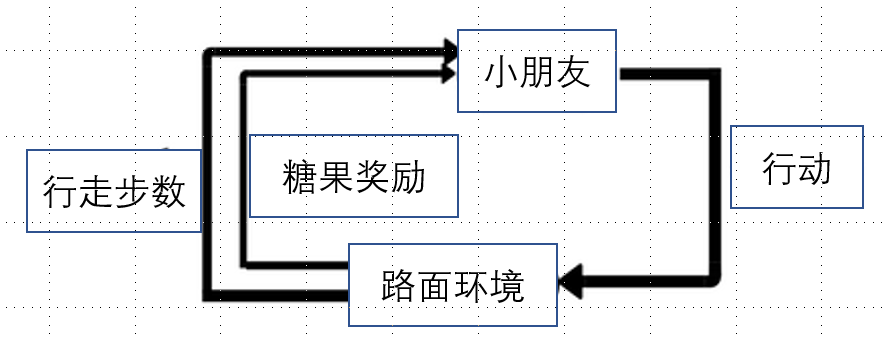
第一幅图是介绍强化学习常见的基本原理图,其中:
Agent代理:一个假定的实体,可以在环境中执行操作以获取一定的回报,类比例子里的小朋友
Environment环境:代理必须面对的场景。
reward奖励:代理执行特定操作或任务时,给予的回报。
state状态:状态是指代理执行动作后返回的状态。
action行动:代理根据环境执行操作
2.与其他机器学习方法的比较
强化学习属于一类更大的机器学习算法。以下是 机器学习方法的类型的描述。
让我们看一下RL和其他代码之间的比较:
监督与强化学习:在监督学习中,有一个外部“监督者”,该监督者了解环境,并与代理共享该知识以完成任务。但是存在一些问题,在某些情况下子任务的组合如此之多,代理可以尝试的方法非常多。因此,创建“主管”几乎是不切实际的。例如,在国际象棋游戏中,可以进行成千上万的动作。因此,创建可以发挥作用的知识库是一项繁琐的任务。在这些问题中,学习自己的经验并从中获得知识是更可行的。这可以说是强化学习和监督学习的主要区别。
无监督与强化学习:在强化学习中,存在从输入到输出的映射,这在无监督学习中是不存在的。在无监督学习中,主要任务是找到基础模式而不是映射。例如,如果任务是向用户推荐新闻文章,则无人监督的学习算法将查看该人以前阅读过的类似文章,并向他们推荐相似文章。强化学习算法将先建议很少的新闻文章然后获取用户的喜欢与否反馈,然后构建一个“知识图”,在未来给用户推荐更合口味的文章。
还有第四种类型的机器学习方法,称为半监督学习,它本质上是监督学习和无监督学习的结合。
3.解决强化学习问题的原理框架
说了这么多,很多小伙伴大概已经了解强化学习了,好奇怎么实现呢?听起来很难吧?那和flare老师平时的课程一样,咱们一定要尝试实战实现一下,加深理解。当然,文章篇幅有限,不做过于细致的原理分析。
那我们先来通过一个路径规划问题来说说基本原理框架:
这是最短路径问题的表示。任务是从地点A到地点F,且希望成本尽可能低。两个位置之间的每个边上的数字表示当前路径前行的付出或回报成本。负成本可以理解为有所回报(糖果奖励)。我们将最终的目标可以理解为指定的路线前进后得到的总回报。
这里,
- 状态集是节点,即{A,B,C,D,E,F}
- 要做的动作是从一个地方到另一个地方,即{A-> B,C-> D等}
- 奖励函数是各边表示的值,即成本
- 策略是完成任务的“途径”,即{A-> C-> F}
- 现在假设我们在位置A,唯一可见的路径是我们的下一个目的地,并且在此阶段尚不知道的其他任何东西(又称可观察空间)
我们可以采取贪婪的方法,并采取最佳可能的下一步,即从{A->(B,C,D,E)}的子集中的{A-> D}开始。同样,现在你在D位置,并且想转到F位置,可以从{D->(B,C,F)}中进行选择。我们看到{D-> F}具有最低的成本,因此我们采取了这条道路。
所以在这里,我们的策略是采用{A-> D-> F},我们的值是-120。
恭喜你!您刚刚实现了强化学习算法。该算法称为epsilon greedy,从字面上看,它是解决问题的一种贪婪方法。现在,如果我们希望再次从A位置移至F位置,则始终选择相同的策略,agent发现这个行动奖励高,以后都这么干!
4、强化学习的实现
任何一种机器学习方法都很多种细分的技术,我们今天就和大家介绍实现强化学习的Q学习算法。
Q学习的伪代码:
- 初始化值表’ Q(s,a)
- 观察当前状态“ s”
- 根据一项行动选择策略(例如epsilon greedy),为该状态选择一项行动“ a”
- 采取行动,观察奖励 “ r” 和新状态 “ s”
- 使用观察到的奖励和下一状态可能的最大奖励来更新状态的值。根据上述公式和参数进行更新
- 将状态设置为新状态,然后重复该过程,直到达到终端状态为止
Q学习的简单描述可以总结如下: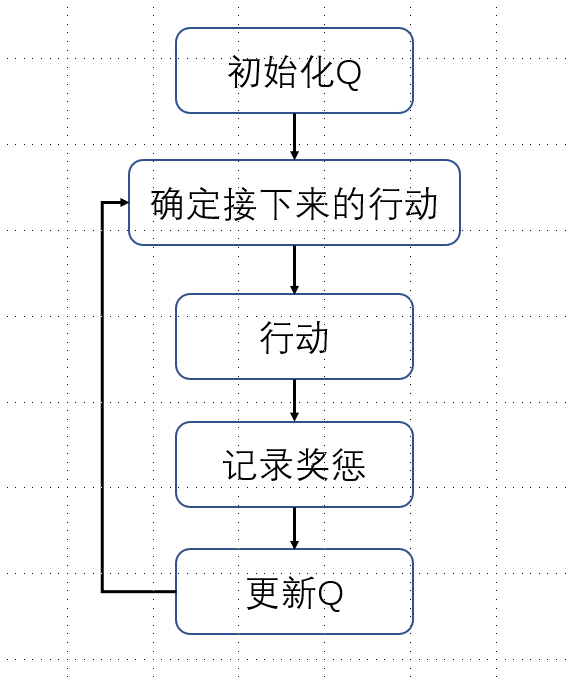
实战案例我们直接基于RL官方介绍的一阶倒立摆的实现,简单来说,就是让图中的杆子保持竖立状态!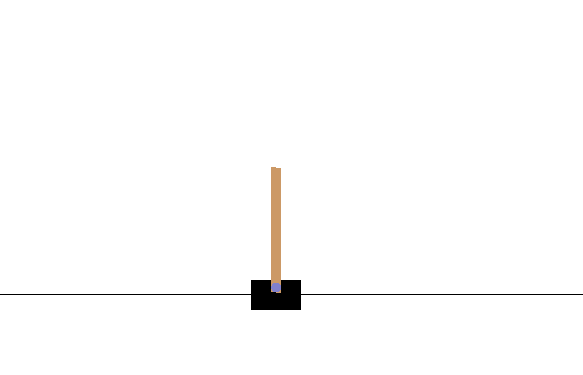
如果还不是很明白,请点击 视频链接。
接下来,start Coding!
1、安装强化学习依赖包:pip install keras-rl
安装运行试验依赖包:pip install gym
2、引入需要使用的库
import numpy as np
import gym
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
3、设置环境参数
ENV_NAME = 'CartPole-v0'
# 建立环境并提取出倒立摆问题中可用的操作数
env = gym.make(ENV_NAME)
np.random.seed(123)
env.seed(123)
nb_actions = env.action_space.n```
接下来,建立一个神经网络模型
在这里输入代码
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
print(model.summary())
接下来,我们配置并编译代理。我们将策略设置为Epsilon Greedy,并将内存设置为顺序内存,因为我们要存储执行的操作的结果以及每个操作获得的奖励。
policy = EpsGreedyQPolicy()
memory = SequentialMemory(limit=50000, window_length=1)
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10,target_model_update=1e-2, policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
模型训练并可视化效果
dqn.fit(env, nb_steps=5000, visualize=True, verbose=2)
测试模型结果
dqn.test(env, nb_episodes=5, visualize=True)
为了让大家更方便的看到效果,flare老师上传了视频, 点这里。
看完这篇文章,是不是发现强化学习既有趣又简单。
finally:flare老师的实战课程 “零基础入门人工智能:系统学习+实战”课程已经上线,欢迎小伙伴们订阅,和flare老师一起学习AI,掌握AI工具,解决实际问题。
还可以分享给朋友。
共同学习,写下你的评论
评论加载中...
作者其他优质文章

flare_zhao
关注作者,订阅最新文章
阅读免费教程
-
 Python 办公自动化教程17个小节 24744 834
Python 办公自动化教程17个小节 24744 834 -
 Python 算法入门教程15个小节 26110 1022
Python 算法入门教程15个小节 26110 1022 -
 Python 进阶应用教程38个小节 62560 975
Python 进阶应用教程38个小节 62560 975
100积分直接送
付费专栏免费学
大额优惠券免费领