- +1
微信版大语言模型来了:跨时空对话李白、教你高情商说话
原创 关注前沿科技 量子位 收录于合集#微信 2 个 #大模型 6 个
鱼羊 梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
大规模语言模型,微信版,来了!
并且甫一登场,就没藏着掖着:
论文、API接口、在线试玩网站……一条龙全都齐备。
续写文本、阅读理解等常规任务就不说了,这个名叫WeLM的AI,竟然直接让我和李白跨时空聊起了杜甫:
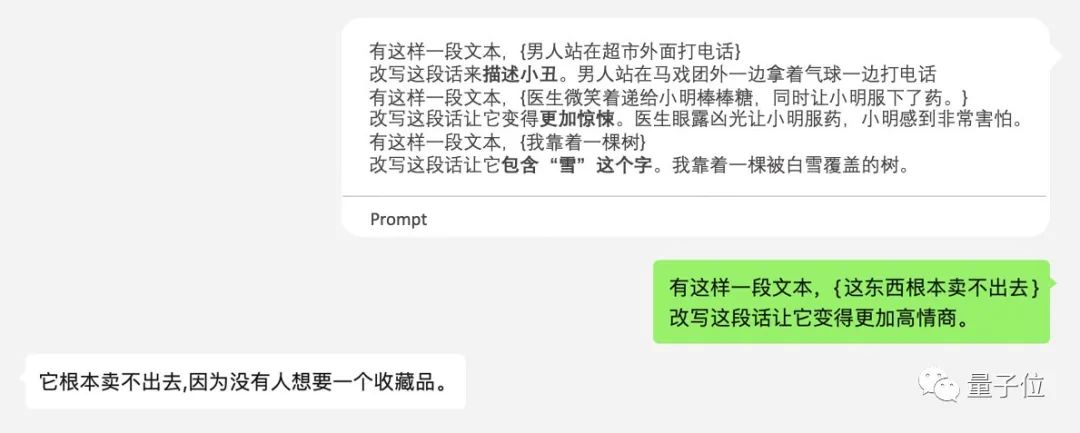
我:现在有一首关于你的歌,其中一句歌词是「要是能重来,我要选李白」,请问你自己有什么看法?
李白:我要选杜甫。这还不算完,WeLM甚至还治好了我不会聊天的毛病,分分钟教会我如何高情商说话。
这么一个AI,参数量不算大,目前处于百亿水平。
但值得关注的是,实验结果显示,它在18个中文语言任务里,效果堪比参数量是其25倍的模型。
是不是有点手痒想上手一试了?先奉上链接,咱们再仔细说说,这波微信是怎么做到的。
体验链接:https://welm.weixin.qq.com/docs/playground/
API接口:https://welm.weixin.qq.com/docs/api/
论文地址:https://arxiv.org/abs/2209.10372
「学富五车」的大模型
微信语言大模型WeLM,全名Well-Read Language Model,也就是「学富五车的语言模型」。
在翻译任务上,WeLM不光可以做到基本的,甚至三语夹杂也难不倒它。

在文本续写任务上,只需给出开头就能生成适应不同风格的文本。

这种多语言、多任务能力是怎么做到的?
其实WeLM与著名的GPT-3是同类,都是自回归解码器结构,微信团队选择这种结构就是看中其在海量数据中掌握无穷范式的能力。
在具体实现方法上,WeLM还有两项特色。
一是采用RoPE相对位置编码,与传统的固定位置编码相比能更好处理长文本,比如理解整篇文章甚至整本书。
二是使用62k个token的SentencePiece并保留其中的空格和Tab,这样更有利于下游任务。
使用这些方法,WeLM总共设计了从13亿到100亿参数的三个版本,可按需调用。

其中100亿参数的满血版WeLM在14项中文任务中整体表现超过同大小的模型,甚至在零样本任务上超过比它大25倍的模型。
这其中最大的秘诀就是精心准备的高质量训练数据上充分训练,也就是「学富五车」的含义所在。
高质量训练数据包括从Common Crawl下载的近两年中文网页、大量书籍、新闻、论坛数据和学术论文。
收集到的数据总量超过10TB,其中包含750G英文数据,中文中夹杂的英日韩语为了语义连贯也全部保留。
不过这还不算完,需要经过清洗、去重等一系列步骤才能算得上是高质量数据。
首先是去除噪声和脏数据,结合使用规则和模型检测后,超过87%的数据被过滤。
再利用SimHash算法去重,进一步过滤掉40%的数据。
接下来要去除一切和测评相关的数据,保证公平性,以 17-gram 为检测重复粒度再次过滤了0.15%的数据。
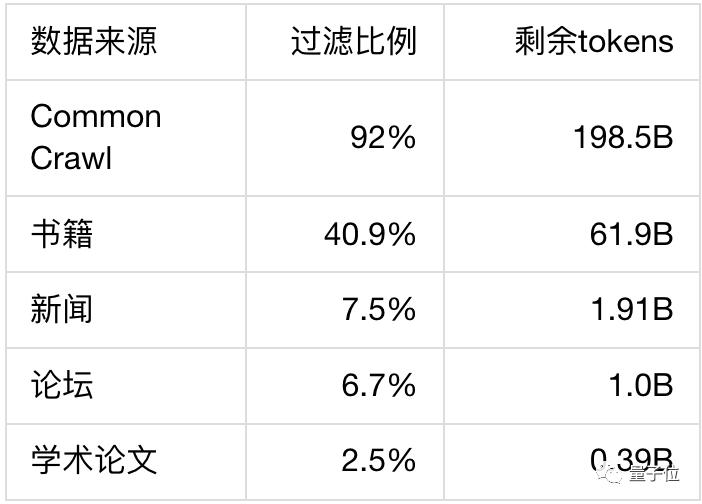
一系列处理后留下的数据量为262B tokens,最后再对这些数据进行不同比重的采样,使数据平滑分布在各个话题上。
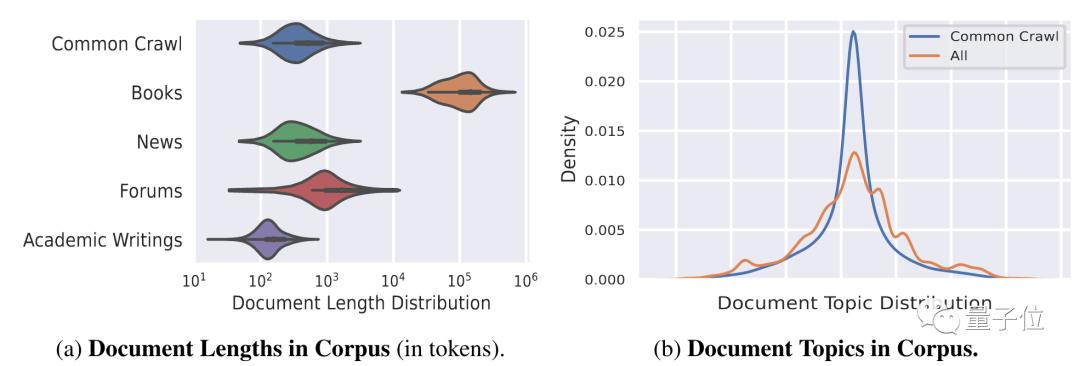
对于预训练,团队认为当今多数大模型的训练都不够充分,WeLM 100亿参数版的训练量基本与1750亿的GPT-3相当(300B tokens),在128张A100上训练用了大概24天时间。
为了保证训练效率,WeLM在训练过程中还使用了完全可原地复现的形式,不管发生任何问题都能从最近的checkpoint恢复。
自1750亿参数的GPT-3之后,语言模型规模越来越大,到今年谷歌的PaLM已经达到5400亿,中文大模型同样有这个趋势。
可以看出微信团队选择了另一条路线,以高质量训练数据和高效训练做到「四两拨千斤」的效果。
到这一步WeLM已经有了不错的表现,不过接下来这个步骤再次将其零样本泛化能力提到新的高度。
研究团队针对76个数据集各人工撰写10-20个Prompt,将原任务中的文本关系的标签和输入信息转化成流畅通顺的自然语言形式,更符合自回归语言模型的训练形式。
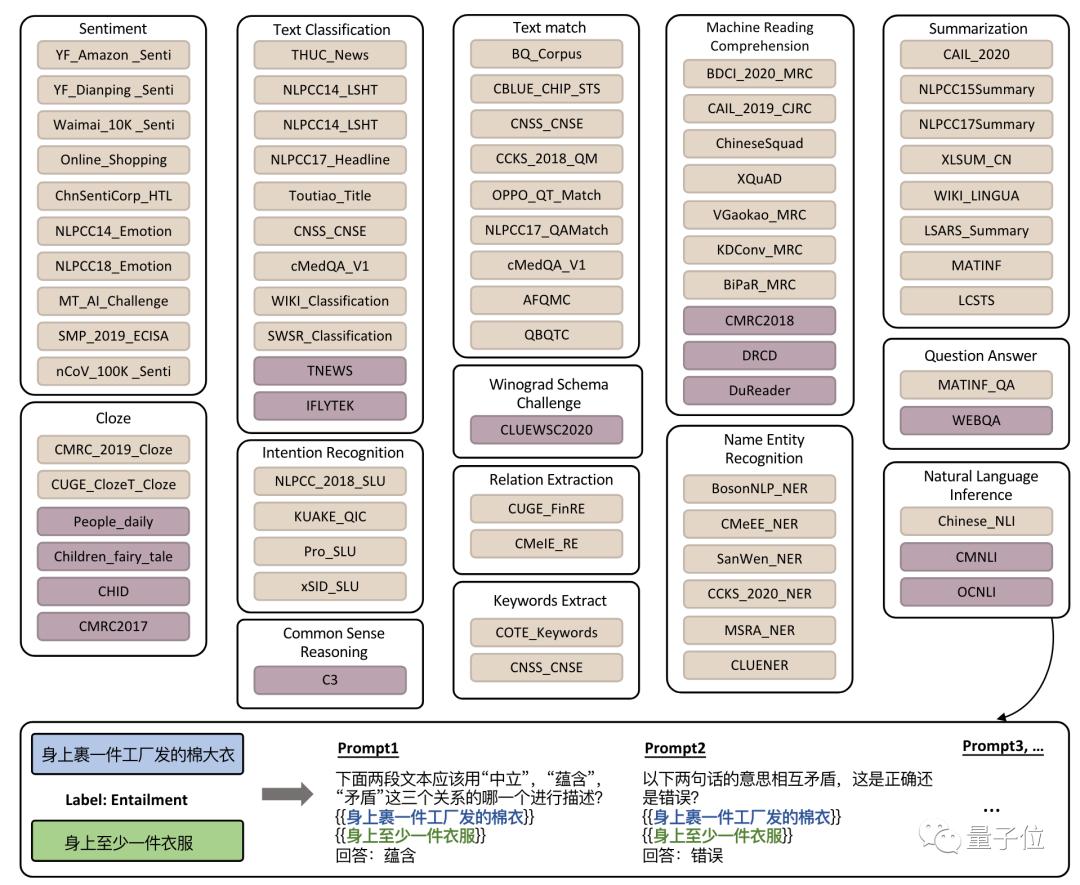
使用这些Prompt对模型微调后,相当于让模型学会了面对多样的Prompt该做什么。如果遇到相似Prompt形式的全新任务,也可以有更稳定的表现。
实验证明,在全量数据上微调后的模型在新的NLP任务上具备更优秀的零样本迁移能力,同时也使得微调变为一项一劳永逸的工作。
最后,研究团队还测试了WeLM的三个额外能力。
通过提供示例,WeLM可以对自己的决策作出解释,不过这种能力不太稳定,还需要进一步探索。
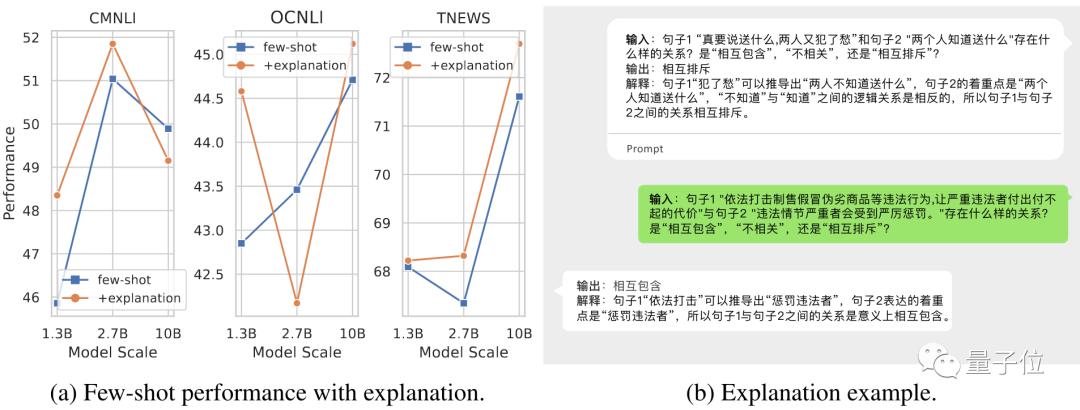
通过简单提问,WeLM可以对结果进行自我纠正和检查能力,为后续提高性能提供了可能方向。

WeLM还表现出一定的记忆能力,如果输入内容完美匹配前文,即使内容很长、出现频次很低,模型依然可以准确的生成剩下的部分。
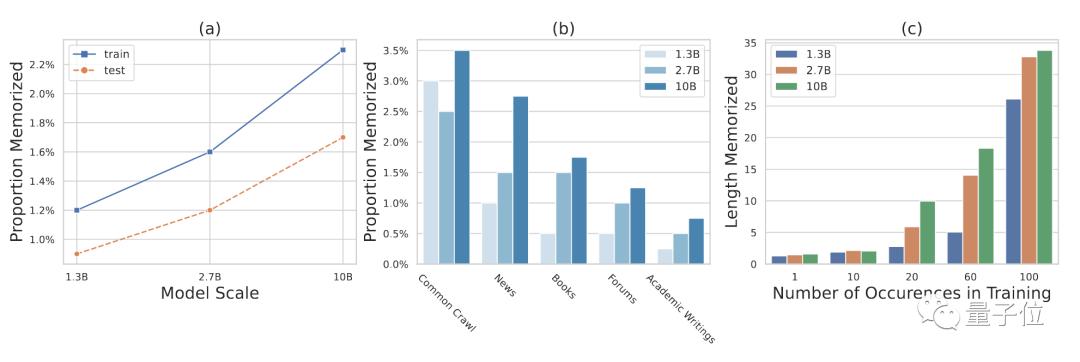
最后再来总结一下,WeLM精通中文的同时掌握英日韩等多种外语、可以通过少样本或零样本学习执行全新任务,同时以合理尺寸做到与25倍参数量的模型相媲美使用成本较低,总之就是奔着实用性和大规模落地去的。
同步开放在线体验与API,也是希望有想法的开发者能方便的用起来,让WeLM大模型真正实用的工具。
WeLM怎么用
具体来说,WeLM线上Demo目前释出的功能包括:对话-采访、阅读理解、翻译、改写、续写以及自由任务。
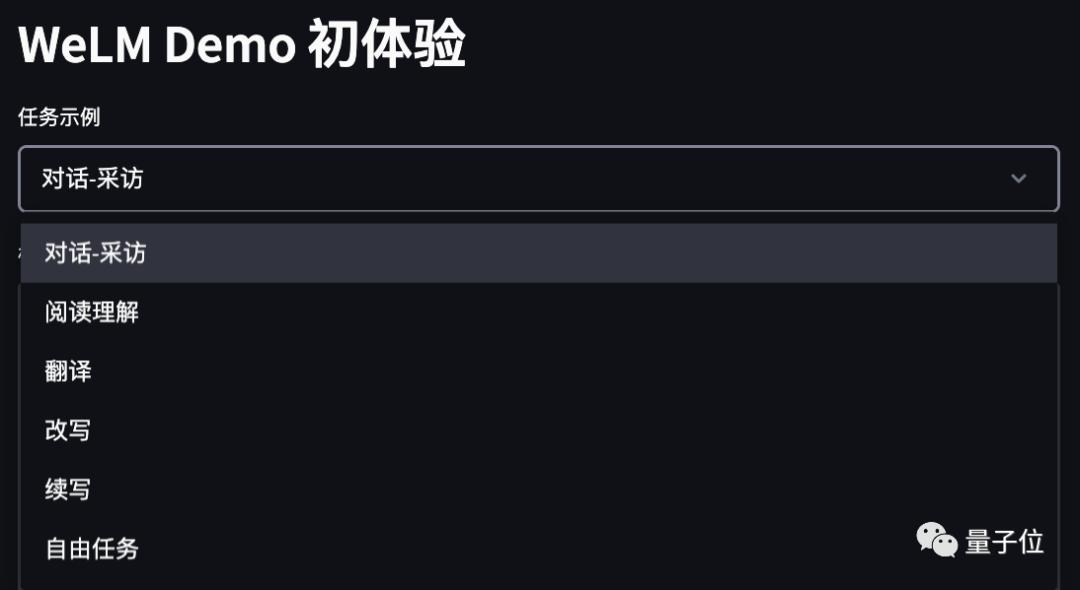
在正式开始跟WeLM玩耍之前,记得要先给模型扔一段简单的「范文」,也就是「prompt」。
在线网站会给出一些默认的prompt,你也可以自行修改设计。需要遵循的设计原则是:
第一,描述清楚;第二,例子具备代表性(多个例子更好)。
以文本分类任务为例,prompt应该长这样:

其中的技巧包括,首先,把分类任务用自然语言清晰地表达出来,在上面这个示例中,「微博」即为输入,「类别」即为输出。
其次,在第一句的指令型描述中,需要把可能的分类结果都列出来。
最后,如果效果不佳,可以尝试加入更多例子,让WeLM更清楚你到底想要做怎样的任务。
另外,正如前文所说,WeLM拥有零样本学习能力。
所以直接把它当作问答搜索引擎来用,也不是不行(手动狗头)。
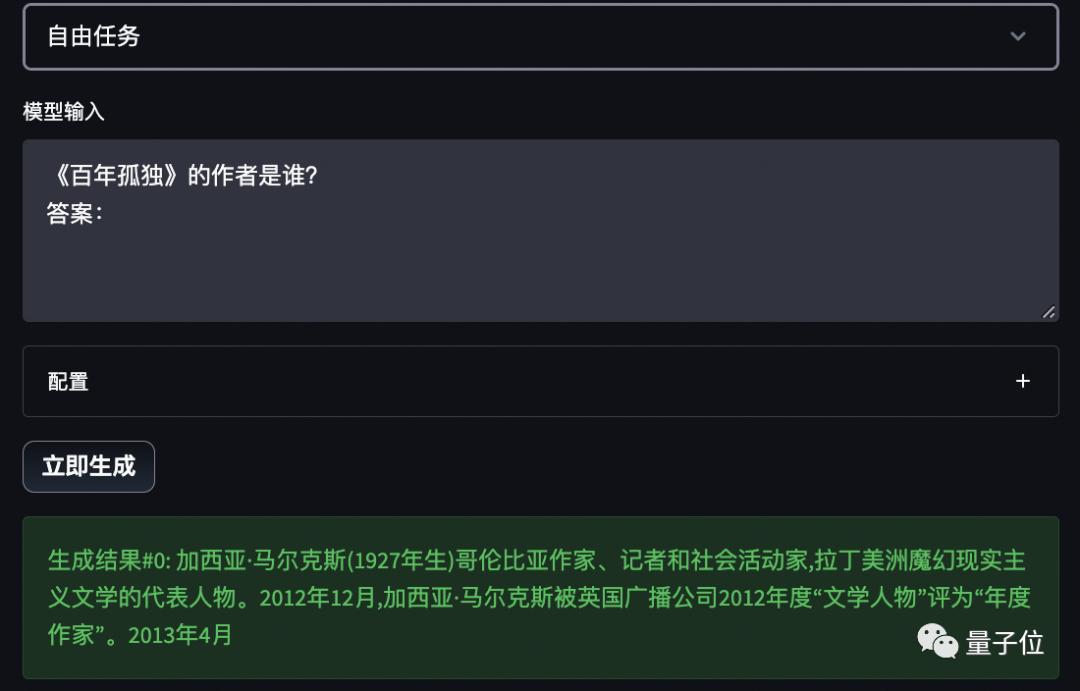
如果你还想得到更多样化的生成结果,token数量、temperature等参数均可调整。
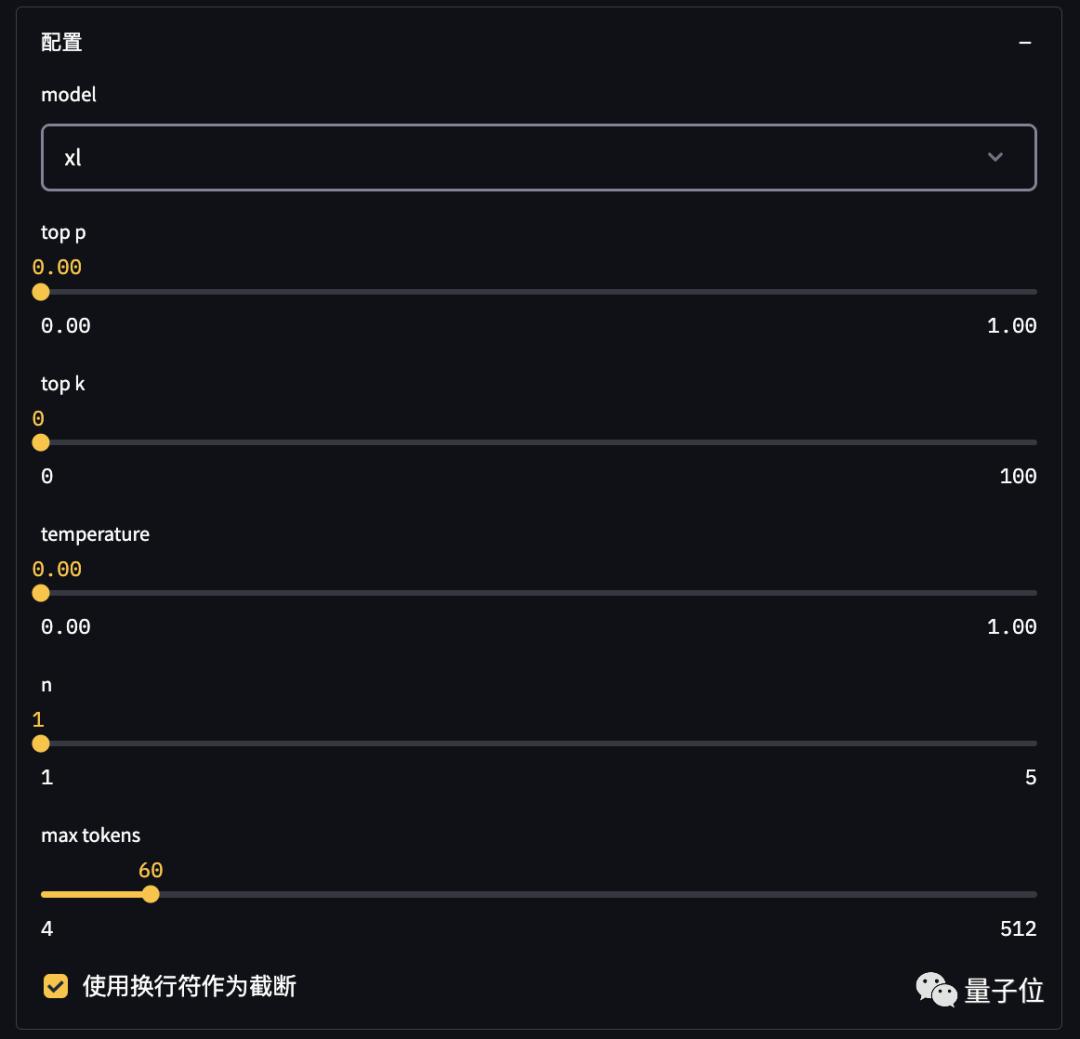
更重要的一点是,WeLM已开放API接口 。也就是说,如果身为开发者的你想在自己的App里用上这个大模型,填写调查问卷注册即可。
One More Thing
说起来,这样的大模型要是真的落地应用了,妈妈岂不是再也不用担心我因为不会聊天而母胎solo ?
比如说……
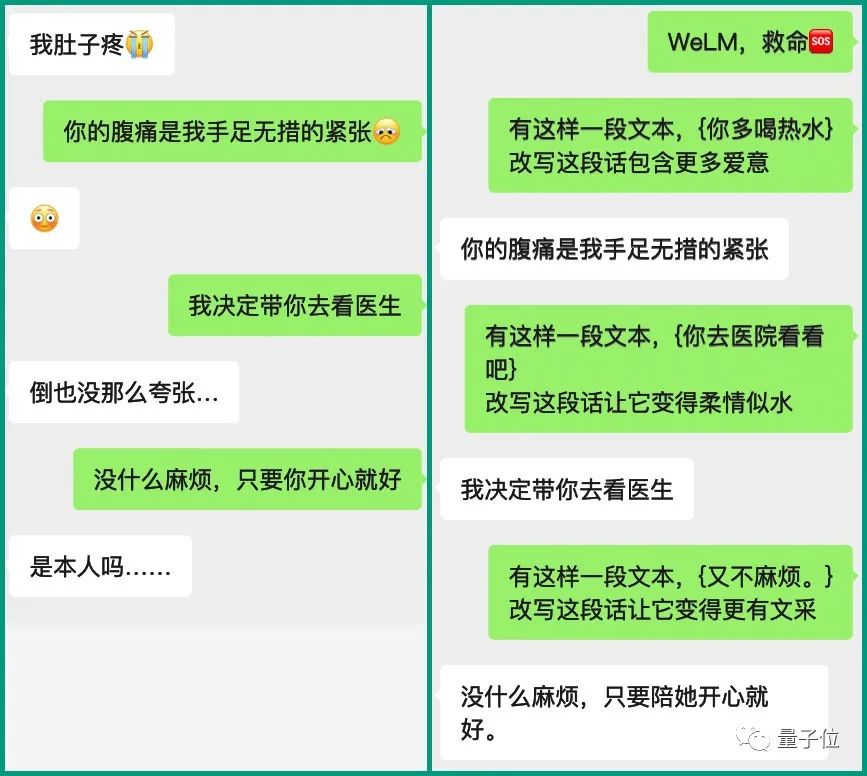
你还有什么有趣的脑洞?大胆招呼起来~
— 完 —
原标题:《微信版大语言模型来了:跨时空对话李白、教你高情商说话,API在线试玩全都有》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。


扫码下载澎湃新闻客户端
Android版
iPhone版
iPad版
- 澎湃新闻微博
- 澎湃新闻公众号

- 澎湃新闻抖音号
- IP SHANGHAI
- SIXTH TONE
- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
沪ICP备14003370号
沪公网安备31010602000299号
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

