- +1
7 Papers & Radios | MiniGPT-4看图聊天、还能草图建网站;视频版Stab…
机器之心 & ArXiv Weekly
参与:楚航、罗若天、梅洪源
本周论文包括慕尼黑大学、英伟达等机构的研究者利用潜在扩散模型(latent diffusion model, LDM)实现了高分辨率的长视频合成;MiniGPT-4 发布,能看图聊天、还能草图建网站。
目录
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
MiniGPT-4:Enhancing Vision-language Understanding with Advanced Large Language Models
OpenAssistant Conversations - Democratizing Large Language Model Alignment
Inpaint Anything: Segment Anything Meets Image Inpainting
Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
Plan4MC: Skill Reinforcement Learning and Planning for Open-World Minecraft Tasks
T2Ranking: A large-scale Chinese Benchmark for Passage Ranking
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
作者:Andreas Blattmann 、 Robin Rombach 等
论文地址:https://arxiv.org/pdf/2304.08818.pdf
摘要:近日慕尼黑大学、英伟达等机构的研究者利用潜在扩散模型(latent diffusion model, LDM)实现了高分辨率的长视频合成。
在论文中,研究者将视频模型应用于真实世界问题并生成了高分辨率的长视频。他们关注两个相关的视频生成问题,一是高分辨率真实世界驾驶数据的视频合成,其在自动驾驶环境中作为模拟引擎具有巨大潜力;二是文本指导视频生成,用于创意内容生成。
为此,研究者提出了视频潜在扩散模型(Video LDM),并将 LDM 扩展到了计算密集型任务 —— 高分辨率视频生成。与以往视频生成 DM 工作相比,他们仅在图像上预训练 Video LDM(或者使用可用的预训练图像 LDM),从而允许利用大规模图像数据集。
接着将时间维度引入潜在空间 DM、并在编码图像序列(即视频)上仅训练这些时间层的同时固定预训练空间层,从而将 LDM 图像生成器转换为视频生成器(下图左)。最后以类似方式微调 LDM 的解码器以实现像素空间中的时间一致性(下图右)。
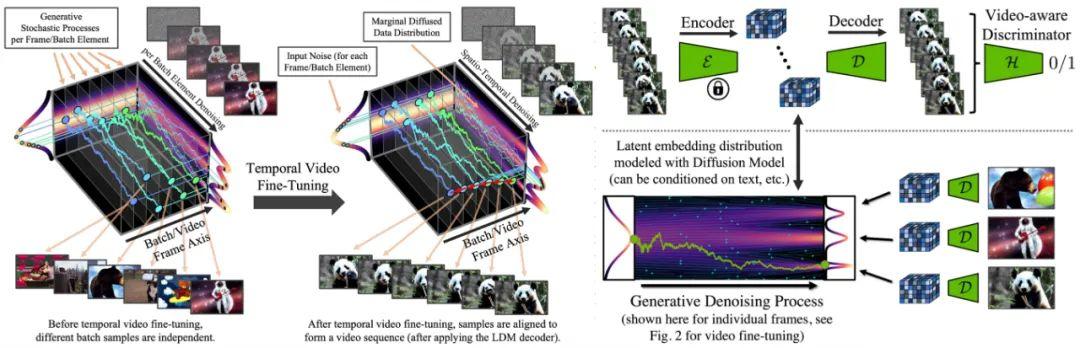
推荐:视频版 Stable Diffusion:英伟达做到最高 1280×2048、最长 4.7 秒。
论文 2:MiniGPT-4:Enhancing Vision-language Understanding with Advanced Large Language Models
作者:朱德尧、陈军、沈晓倩、李祥、Mohamed H. Elhoseiny
论文地址:https://minigpt-4.github.io/
摘要:来自阿卜杜拉国王科技大学(KAUST)的团队上手开发了一个 GPT-4 的类似产品 ——MiniGPT-4。MiniGPT-4 展示了许多类似于 GPT-4 的能力,例如生成详细的图像描述并从手写草稿创建网站。此外,作者还观察到 MiniGPT-4 的其他新兴能力,包括根据给定的图像创作故事和诗歌,提供解决图像中显示的问题的解决方案,根据食品照片教用户如何烹饪等。
MiniGPT-4 使用一个投影层将一个冻结的视觉编码器和一个冻结的 LLM(Vicuna)对齐。MiniGPT-4 由一个预训练的 ViT 和 Q-Former 视觉编码器、一个单独的线性投影层和一个先进的 Vicuna 大型语言模型组成。MiniGPT-4 只需要训练线性层,用来将视觉特征与 Vicuna 对齐。
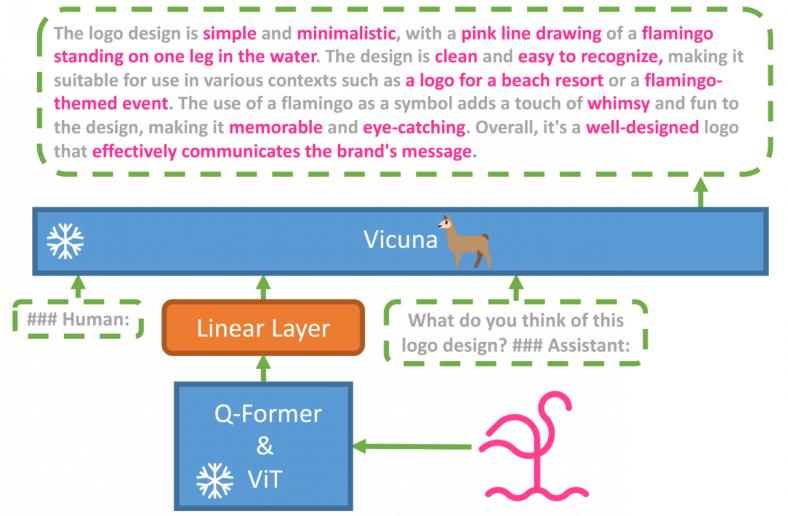
示例展示:从草图创建网站。

推荐:3 天近一万 Star,无差体验 GPT-4 识图能力,MiniGPT-4 看图聊天、还能草图建网站。
论文 3:OpenAssistant Conversations - Democratizing Large Language Model Alignment
作者:Andreas Köpf、Yannic Kilcher 等
论文地址:https://drive.google.com/file/d/10iR5hKwFqAKhL3umx8muOWSRm7hs5FqX/view
摘要:为了使大规模对齐研究民主化,来自 LAION AI 等机构(Stable diffusion 使用的开源数据就是该机构提供的。)的研究者收集了大量基于文本的输入和反馈,创建了一个专门训练语言模型或其他 AI 应用的多样化和独特数据集 OpenAssistant Conversations。
该数据集是一个由人工生成、人工注释的助理式对话语料库,覆盖了广泛的主题和写作风格,由 161443 条消息组成,分布在 66497 个会话树中,使用 35 种不同的语言。该语料库是全球众包工作的产物,涉及超过 13500 名志愿者。对于任何希望创建 SOTA 指令模型的开发者而言,它都是一个非常宝贵的工具。并且任何人都可以免费访问整个数据集。
此外,为了证明 OpenAssistant Conversations 数据集的有效性,该研究还提出了一个基于聊天的助手 OpenAssistant,其可以理解任务、与第三方系统交互、动态检索信息。可以说这是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。
结果显示,OpenAssistant 的回复比 GPT-3.5-turbo (ChatGPT) 更受欢迎。
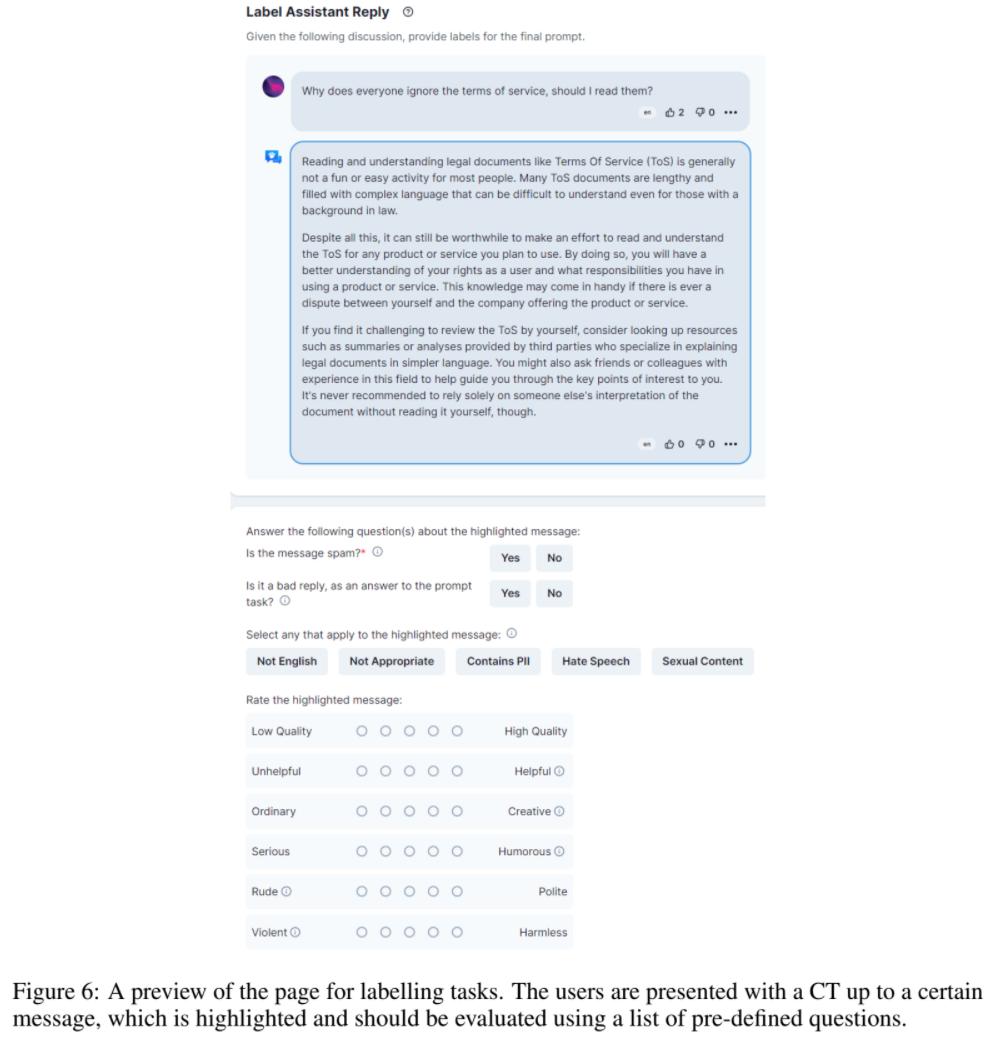
OpenAssistant Conversations 数据是使用 web-app 界面收集的,包括 5 个步骤:提示、标记提示、将回复消息添加为提示器或助手、标记回复以及对助理回复进行排名。
推荐:ChatGPT 全球最大开源平替。
论文 4:Inpaint Anything: Segment Anything Meets Image Inpainting
作者:Tao Yu、Runseng Feng 等
论文地址:http://arxiv.org/abs/2304.06790
摘要:来自中国科学技术大学和东方理工高等研究院的研究团队,基于 SAM(Segment Anything Model),提出「修补一切」(Inpaint Anything,简称 IA)模型。区别于传统图像修补模型,IA 模型无需精细化操作生成掩码,支持了一键点击标记选定对象,IA 即可实现移除一切物体(Remove Anything)、填补一切内容(Fill Anything)、替换一切场景(Replace Anything),涵盖了包括目标移除、目标填充、背景替换等在内的多种典型图像修补应用场景。
IA 拥有三个主要功能:(i) 移除一切(Remove Anything):用户只需点击一下想要移除的物体,IA 将无痕地移除该物体,实现高效「魔法消除」;(ii) 填补一切(Fill Anything):同时,用户还可以进一步通过文本提示(Text Prompt)告诉 IA 想要在物体内填充什么,IA 随即通过驱动已嵌入的 AIGC(AI-Generated Content)模型(如 Stable Diffusion [2])生成相应的内容填充物体,实现随心「内容创作」;(iii) 替换一切(Replace Anything):用户也可以通过点击选择需要保留的物体对象,并用文本提示告诉 IA 想要把物体的背景替换成什么,即可将物体背景替换为指定内容,实现生动「环境转换」。IA 的整体框架如下图所示:
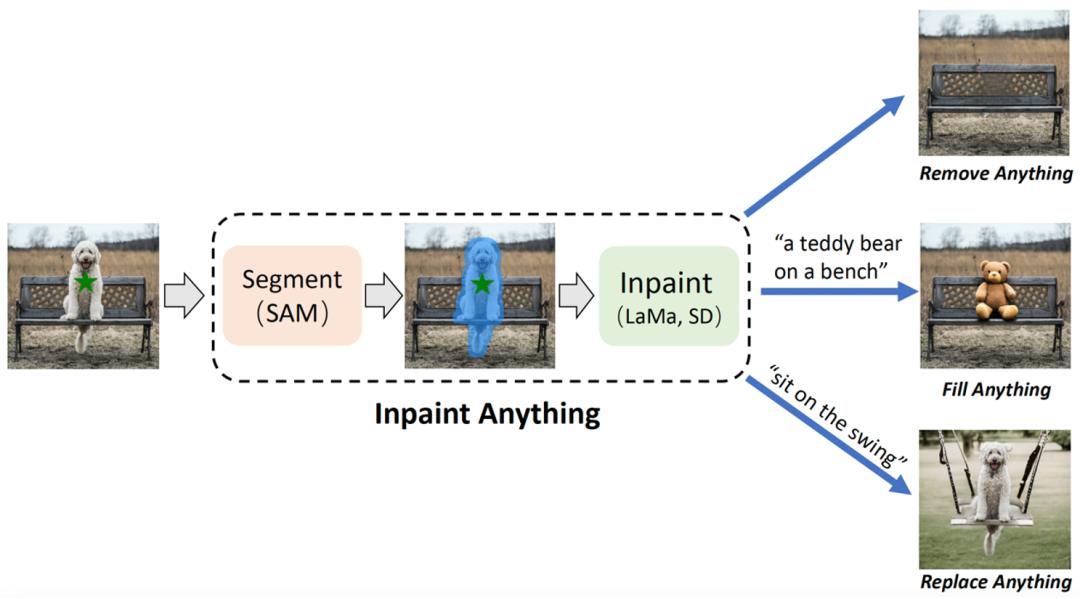
推荐:无需精细标记,单击物体实现物体移除、内容填补、场景替换。
论文 5:Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
作者:Feng Liang 、 Bichen Wu 等
论文地址:https://arxiv.org/pdf/2210.04150.pdf
摘要:Meta、UTAustin 联合提出了新的开放语言风格模型(open-vocabulary segmentation, OVSeg),它能让 Segment Anything 模型知道所要分隔的类别。
从效果上来看,OVSeg 可以与 Segment Anything 结合,完成细粒度的开放语言分割。比如下图 1 中识别花朵的种类:sunflowers (向日葵)、white roses (白玫瑰)、 chrysanthemums (菊花)、carnations (康乃馨)、green dianthus (绿石竹)。

推荐:Meta/UTAustin 提出全新开放类分割模型。
论文 6:Plan4MC: Skill Reinforcement Learning and Planning for Open-World Minecraft Tasks
作者:Haoqi Yuan、Chi Zhang 等
论文地址:https://arxiv.org/abs/2303.16563
摘要:北京大学和北京智源人工智能研究院的团队提出了在无专家数据的情况下高效解决 Minecraft 多任务的方法 Plan4MC。作者结合强化学习和规划的方法,将解决复杂任务分解为学习基本技能和技能规划两个部分。作者使用内在奖励的强化学习方法训练三类细粒度的基本技能。智能体使用大型语言模型构建技能关系图,通过图上的搜索得到任务规划。实验部分,Plan4MC 目前可以完成 24 个复杂多样任务,成功率相比所有的基线方法有巨大提升。

推荐:用 ChatGPT 和强化学习玩转《我的世界》,Plan4MC 攻克 24 个复杂任务。
论文 7:T2Ranking: A large-scale Chinese Benchmark for Passage Ranking
作者:Xiaohui Xie、Qian Dong 等
论文地址:https://arxiv.org/abs/2304.03679
摘要:段落排序是信息检索领域中十分重要且具有挑战性的话题,受到了学术界和工业界的广泛关注。段落排序模型的有效性能够提高搜索引擎用户的满意度并且对问答系统、阅读理解等信息检索相关应用有所助益。在这一背景下,例如 MS-MARCO,DuReader_retrieval 等一些基准数据集被构建用于支持段落排序的相关研究工作。然而常用的数据集大部分都关注英文场景,对于中文场景,已有的数据集在数据规模、细粒度的用户标注和假负例问题的解决上存在局限性。在这一背景下,该研究基于真实搜索日志,构建了一个全新的中文段落排序基准数据集:T2Ranking。
T2Ranking 由超过 30 万的真实查询和 200 万的互联网段落构成,并且包含了由专业标注人员提供的 4 级细粒度相关性标注。目前数据和一些 baseline 模型已经公布在 Github,相关研究工作已作为 Resource 论文被 SIGIR 2023 录用。
推荐:30 万真实查询、200 万互联网段落,中文段落排序基准数据集发布。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天、梅洪源发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. Task-oriented Document-Grounded Dialog Systems by HLTPR@RWTH for DSTC9 and DSTC10. (from Hermann Ney)
2. Exploring the Trade-Offs: Unified Large Language Models vs Local Fine-Tuned Models for Highly-Specific Radiology NLI Task. (from Wei Liu, Dinggang Shen)
3. On the Robustness of Aspect-based Sentiment Analysis: Rethinking Model, Data, and Training. (from Tat-Seng Chua)
4. Stochastic Parrots Looking for Stochastic Parrots: LLMs are Easy to Fine-Tune and Hard to Detect with other LLMs. (from Rachid Guerraoui)
5. Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models. (from Kai-Wei Chang, Song-Chun Zhu, Jianfeng Gao)
6. MER 2023: Multi-label Learning, Modality Robustness, and Semi-Supervised Learning. (from Meng Wang, Erik Cambria, Guoying Zhao)
7. GeneGPT: Teaching Large Language Models to Use NCBI Web APIs. (from Zhiyong Lu)
8. A Survey on Biomedical Text Summarization with Pre-trained Language Model. (from Sophia Ananiadou)
9. Emotion fusion for mental illness detection from social media: A survey. (from Sophia Ananiadou)
10. Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes. (from Christopher Ré)
本周 10 篇 CV 精选论文是:
1. NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models. (from Antonio Torralba)
2. Align-DETR: Improving DETR with Simple IoU-aware BCE loss. (from Xiangyu Zhang)
3. Exploring Incompatible Knowledge Transfer in Few-shot Image Generation. (from Shuicheng Yan)
4. Learning Situation Hyper-Graphs for Video Question Answering. (from Mubarak Shah)
5. Video Generation Beyond a Single Clip. (from Ming-Hsuan Yang)
6. A Data-Centric Solution to NonHomogeneous Dehazing via Vision Transformer. (from Huan Liu)
7. Neuromorphic Optical Flow and Real-time Implementation with Event Cameras. (from Luca Benini, Davide Scaramuzza)
8. Language Guided Local Infiltration for Interactive Image Retrieval. (from Lei Zhang)
9. LipsFormer: Introducing Lipschitz Continuity to Vision Transformers. (from Lei Zhang)
10. UVA: Towards Unified Volumetric Avatar for View Synthesis, Pose rendering, Geometry and Texture Editing. (from Dacheng Tao)
本周 10 篇 ML 精选论文是:
1. Bridging RL Theory and Practice with the Effective Horizon. (from Stuart Russell)
2. Towards transparent and robust data-driven wind turbine power curve models. (from Klaus-Robert Müller)
3. Open-World Continual Learning: Unifying Novelty Detection and Continual Learning. (from Bing Liu)
4. Learning in latent spaces improves the predictive accuracy of deep neural operators. (from George Em Karniadakis)
5. Decouple Graph Neural Networks: Train Multiple Simple GNNs Simultaneously Instead of One. (from Xuelong Li)
6. Generalization and Estimation Error Bounds for Model-based Neural Networks. (from Yonina C. Eldar)
7. RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment. (from Tong Zhang)
8. Adaptive Consensus Optimization Method for GANs. (from Pawan Kumar)
9. Angle based dynamic learning rate for gradient descent. (from Pawan Kumar)
10. AGNN: Alternating Graph-Regularized Neural Networks to Alleviate Over-Smoothing. (from Wenzhong Guo)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《7 Papers & Radios | MiniGPT-4看图聊天、还能草图建网站;视频版Stable Diffusion来了》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。


扫码下载澎湃新闻客户端
Android版
iPhone版
iPad版
- 澎湃新闻微博
- 澎湃新闻公众号

- 澎湃新闻抖音号
- IP SHANGHAI
- SIXTH TONE
- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
沪ICP备14003370号
沪公网安备31010602000299号
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

