
Until now we discussed navigation and data fetching. Today we're going to talk about parsing in general and HTML parsing in particular.
3. HTML PARSING
We saw how after the initial request to the server, the browser receives a response containing the HTML resources of the webpage we are trying to access (the first chunk of data). Now the job of the browswer will be to start parsing the data.
Parsing means analyzing and converting a program into an internal format that a runtime environment can actually run.
In other words, parsing means taking the code we write as text (HTML, CSS) and transform it into something that the browser can work with. The parsing will be done by the browser engine (not to be confused with the the Javascript engine of the browser).
The browser engine is a core component of every major browser and it's main role is to combine structure (HTML) and style (CSS) so it can draw the web page on our screens. It is also responsible to find out which pieces of code are interactive. We should not think about it like a separate piece of software but as being part of a bigger sofware (in our case, the browser).
There are many browser engines in the wild but the majority of the browsers use one of these three actively developed full engines:
Gecko
It was developed by Mozilla for Firefox. In the past it used to power several other browsers but at the moment, besides Firefox, Tor and Waterfox are the only ones still using Gecko. It is written in C++ and JavaScript, and since 2016, additionally in Rust.
WebKit
It's primarily developed by Apple for Safari. It also powers GNOME Web (Epiphany) and Otter. (surprinsingly enough, on iOS, all browsers including Firefox and Chrome, are also powered by WebKit). It it written in C++.
Blink, part of Chromium
Beginning as a fork of WebKit, it's primarily developed by Google for Chrome. It also powers Edge, Brave, Silk, Vivaldi, Opera, and most other browser projects (some via QtWebEngine). It is written in C++.
Now that we understand who's going to do the parsing, let's see what happens exactly after we receive the first HTML document from the server. Let's assume the document looks like this:
<!doctype HTML>
<html>
<head>
<title>This is my page</title>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
</head>
<body>
<h1>This is my page</h1>
<h3>This is a H3 header.</h3>
<p>This is a paragraph.</p>
<p>This is another paragraph,</p>
</body>
</html>
Even if the request page's HTML is larger than the initial 14KB packet, the browser will begin parsing and attempting to render an experience based on the data it has. HTML parsing involves two steps: tokenization and tree construction (building something called the DOM Tree (Document Object Model)).
Tokenization
It is the lexical analysis and it converts some input into tokens (basic components of source code). Imagine we would take an English text and break it down into words, where the words would be the tokens.
What results at the end of the tokenization process is a series of zero or more of the following tokens: DOCTYPE, start tag (<tag>), end tag (</tag>), self-closing tag (<tag/>), attribute names, values, comments, characters, end-of-file or plain text content within an element.
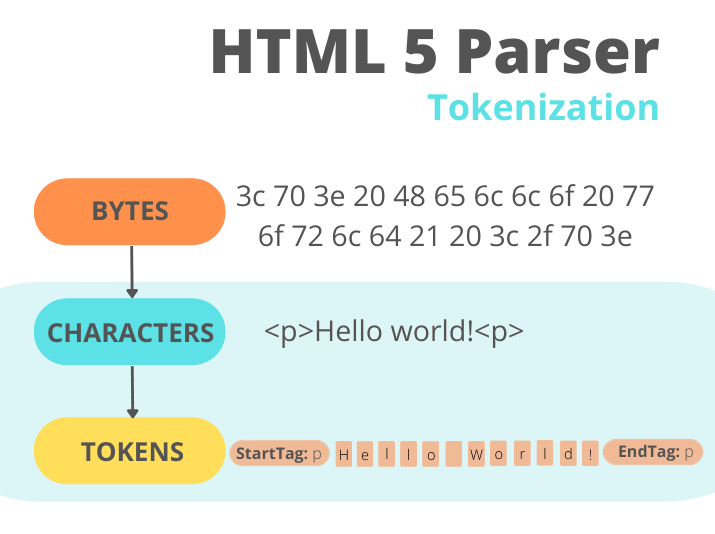
Building the DOM
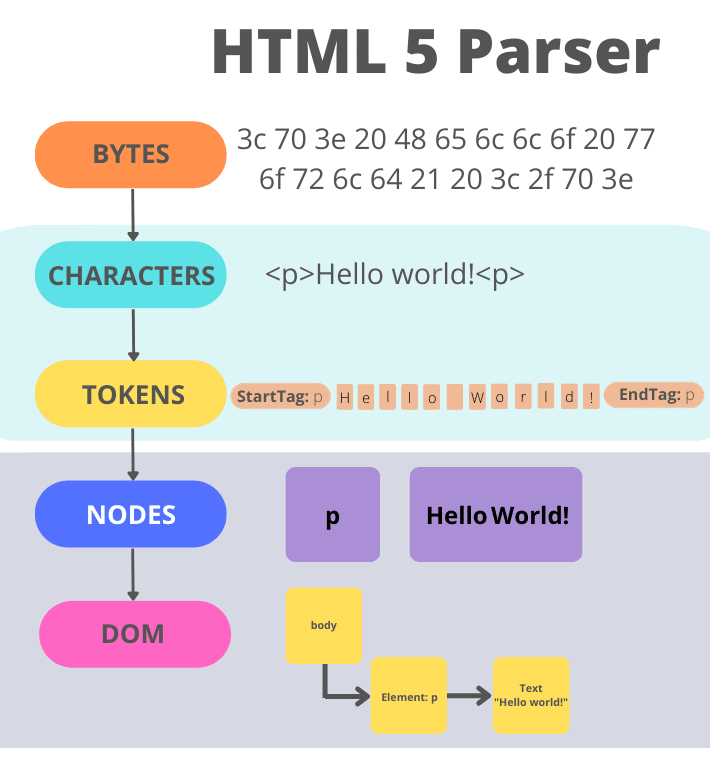
After the first token gets created, tree building starts. This is essentially creating a tree like structure (called the Document Object Model) based on the previously parsed tokens.
The DOM tree describes the content of the HTML document. The <html> element is the first tag and root node of the document tree. The tree reflects the relationships and hierarchies between different tags. We have parent nodes and tags nested within other tags are child nodes. The greater the number of nodes, the longer it will takes to build the DOM tree. Below is the DOM Tree for the HTML document example we got from the server:

In reality, the DOM is more complex than what we see in that schema, but I kept it simple for a better undestanding (also, we'll talk in more detail about the DOM and its importance in a future article).
This building stage is reentrant, meaning that while one token is handled, the tokenizer might be resumed, causing further tokens to be emitted and processed before the first token's processing is complete. From bytes until the DOM is created, the complete process would look like something like this:
The parser works line by line, from top to bottom. When the parser will encounter non-blocking resources (for example images), the browser will request those images from the server and continue parsing. On the other hand, if it encounters blocking-resources (CSS stylesheets, Javascrpt files added in the <head> section of the HTML or fonts added from a CDN ), the parser will stop execution until all those blocking resources are downloaded. That's why, if yu're working with Javascript it is recommended to add your <script> tags at the end of the HTML file, or if you want to keep them in the <head> tag, you should add to them the defer or async attribute (async allows for asynchronous as soon as the script is downloaded and defer allows execution only after the whole document has been parsed.).
Pre-loaders and making the page faster
Internet Explorer, WebKit and Mozilla all implemented pre-loaders in 2008 as a way of dealing with blocking resources, especially scripts (we said earlier, that when encountering a script tag, the HTML parsing would stop until the script is downloaded and executed).
With a pre-loader, when the browser is stuck on a script, a second ligher parser is scanning the HTML for resources that need to be retrieved (stylesheets, scripts etc). The pre-loader then starts retrieving these resources in the background with the aim that by the time the main HTML parser reaches them they may have already been downloaded (in case these resources were already cached, this step is skipped).
Refrence materials:
- MDN Web Docs
- whatwg.org
- Javascript Info
- MDN Web Docs






Top comments (7)
Arika, amazing tutorial!!. Thank you
I'm glad you find it useful.
I am IT teacher in a secondary school. My students are going to do homework of your article: translate to spanish, make a Google Slide and finally translate to English
Thank you!!!
There will be more articles to this series. Wishing them good luck and lots of fun while doing the homework 🤖!
Your diagram of the tokens and nodes is not quite right. The tokenizer doesn't form characters into words and the nodes are not broken into words. So the diagram should look like this:

You are right, for each letter of the word, a token is emitted (I'll correct the diagram a bit later). The node representation was an oversight. Thank you for taking the time to modify the diagram :).
Have you ever tested your words? If script is performing too long stoping the rest part of page, the speculative parser (pre-loader) doesn't work. Speculative parser is stopped before script will be executed.
Why you didn't read the spec and didn't test it?