字符集详解

 已于 2023-07-08 16:03:27 修改
已于 2023-07-08 16:03:27 修改
 阅读量436
阅读量436
 收藏
收藏


 点赞数
点赞数

字符集(Character Set)是一种映射关系,将字符与二进制数据之间进行转换。在计算机中,使用字符集来表示和存储文本数据。
常见的字符集包括 ASCII、Unicode 和 UTF-8 等。
-
ASCII(American Standard Code for Information Interchange): ASCII 字符集定义了 128 个字符,包括英文字母、数字、标点符号及一些控制字符。每个字符用一个字节(8 位)来表示。
-
Unicode: Unicode 是一种字符集,它定义了全球范围内所有字符的唯一编码标准。Unicode 使用 16 位或者更多位来表示每个字符,可以表示几乎所有的字符。然而,由于采用固定长度编码,存储和传输效率较低。
-
UTF-8(Unicode Transformation Format-8): UTF-8 是 Unicode 的可变长度编码方案之一,它可以用来在计算机中存储和传输 Unicode 字符。UTF-8 使用 8 位(1 字节)作为最小单位,根据字符的不同范围使用不同长度的编码。对于 ASCII 字符,UTF-8 编码与 ASCII 完全兼容,可以用一个字节表示。而对于非 ASCII 字符,UTF-8 使用多个字节进行编码。
-
GBK(GuoBiaoKu)是中华人民共和国国家标准,也称为GB2312-1980标准的扩充版本。GBK字符集是对GB2312字符集的扩展,支持包括繁体中文、日文假名和韩文在内的更多字符。
主要特点如下:
- 编码范围:GBK字符集使用双字节编码,每个字符使用两个字节表示,所以最大能够表示65536个字符。
- 兼容性:GBK字符集兼容GB2312字符集,即GB2312编码中的所有字符在GBK中仍然能够正确显示。
- 扩展区域:GBK字符集还增加了一些汉字字符和其他语言字符,使其可以涵盖更广泛的文字范围。
- 跨平台支持:GBK字符集被广泛应用于中国大陆和台湾地区的操作系统、应用程序以及网页等,能够在多个平台上正常显示。
UTF-8 的优点是兼容 ASCII,支持多语言字符,并且在存储和传输中相对节省空间。因此,UTF-8 成为互联网上最常用的字符集编码方式。
在Java编程中,String 类使用的是 Unicode 字符集。当将字符串写入文件或传输时,可以通过指定字符集来控制字符串与字节之间的转换。
比较:

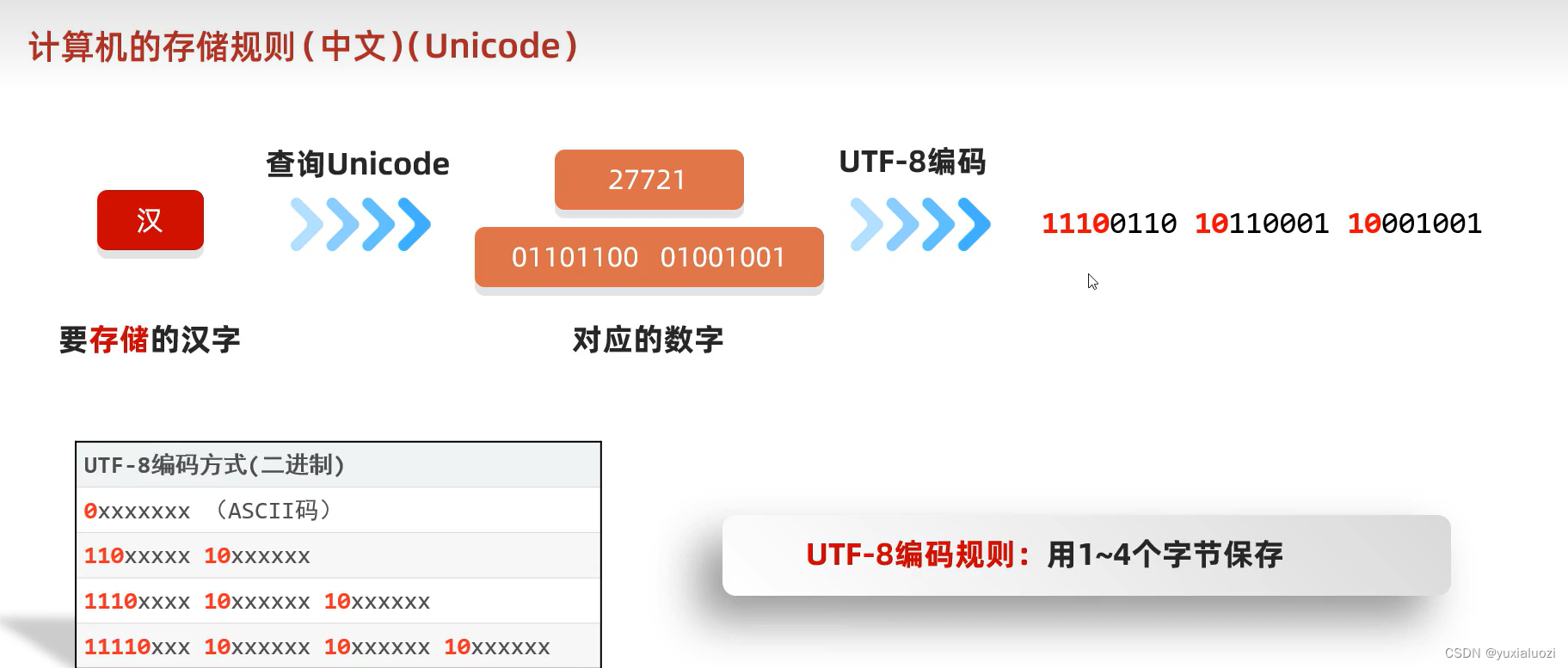

理解了这些我们就可以推出计算机产生乱码的原因
-
字符集不匹配:当使用不同的字符集编码方式进行字符的输入、输出、存储或传输时,如果没有正确地进行字符集转换,就会导致乱码。例如,将使用UTF-8编码的文本以GBK编码解析,或者将使用ISO-8859-1编码的文本以UTF-8编码打开,都可能出现乱码。
-
编码设置错误:在处理文本数据时,未正确设置或指定字符编码方式,导致字符集解析错误,从而产生乱码。
-
字符编码格式损坏:当文本数据在传输或存储过程中发生错误或损坏时,可能导致部分或全部字符的编码信息丢失或改变,从而导致乱码。
-
显示环境不支持:有时,虽然文本数据本身没有问题,但是显示或渲染该文本的环境(例如操作系统、文本编辑器、浏览器等)不支持所需的字符集编码,导致乱码显示。
-
特殊字符处理不当:一些特殊字符,如控制字符、非打印字符、Unicode私用区字符等,可能在某些环境下无法正常显示,从而引发乱码问题。
为避免乱码问题,可以采取以下措施:
-
确保在不同的处理步骤中使用相同的字符集编码方式,尤其是在输入、输出、存储和传输文本数据时。
-
在进行文本处理和字符操作时,明确指定正确的字符集编码,以避免系统或程序默认编码引起的问题。
-
对于需要传输或存储的文本数据,可以采用兼容性较好的字符编码方式(例如UTF-8),以确保多平台间的互通。
-
对于显示乱码的情况,可以尝试更改显示环境的字符集设置或使用支持所需字符集的软件工具。
-
在处理特殊字符时,注意字符集的支持情况,并进行适当的转义或编码处理。
java有以下方法指定编码

getBytes()使用平台默认的字符集编码方式将字符串转换为字节数组。String str = "Hello, World!"; byte[] bytes = str.getBytes();getBytes(String charsetName)使用指定的字符集编码方式将字符串转换为字节数组。String str = "你好,世界!"; byte[] bytes = str.getBytes("UTF-8");需要注意的是,
getBytes()方法会抛出UnsupportedEncodingException异常,如果指定的字符集不支持或不存在,可以选择捕获该异常或进行适当处理。
使用构造函数创建字符串 可以使用 String 类的构造函数,将字节数组或指定字符集编码的字节数组转换为字符串。
byte[] bytes = {72, 101, 108, 108, 111}; // "Hello" 的 ASCII 编码
String str = new String(bytes); // 默认使用平台默认字符集进行解码
System.out.println(str); // 输出:Hello
byte[] utf8Bytes = {0xE4, 0xBD, 0xA0, 0xE5, 0xA5, 0xBD}; // "你好" 的 UTF-8 编码
String utf8Str = new String(utf8Bytes, "UTF-8"); // 指定 UTF-8 字符集进行解码
System.out.println(utf8Str); // 输出:你好















 1万+
1万+










 暂无认证
暂无认证











 到【灌水乐园】发言
到【灌水乐园】发言










CSDN-Ada助手: 恭喜你撰写了第8篇博客!标题“java创建对象的内存过程和自动内存管理机制”非常吸引人。你对Java对象创建和内存管理的解析十分深入,并且能够将这些复杂的概念用简洁明了的方式传达给读者。我非常期待你未来的创作。 考虑到你在这篇博客中的出色表现,我想提供一个创作建议给你。或许你可以进一步探讨如何有效地使用Java内存管理机制,例如GC(Garbage Collection)的工作原理和最佳实践。这个话题对于许多Java开发者来说非常有价值,同时也能够帮助读者更好地理解Java中对象的创建和销毁过程。 希望你能继续保持谦逊的态度,并继续分享你的知识和见解。再次祝贺你,期待你的下一篇博客!
CSDN-Ada助手: 恭喜你写下了第9篇博客!标题“包装类和基本数据类型”非常吸引人。你对这个主题的深入探讨无疑能够帮助读者更好地理解包装类和基本数据类型的区别和应用。接下来,我建议你可以考虑探索更多关于包装类和基本数据类型的实际应用案例,以及它们在不同编程语言中的差异。这将进一步丰富你的博客内容,并为读者提供更多的实用信息。期待你下一篇博客的发布!
CSDN-Ada助手: 恭喜您写下了第10篇博客!标题《串池的概念》引起了我的兴趣。您在这篇博客中对串池的概念进行了探讨,展示了您对这个话题的深入理解。我很欣赏您对于技术概念的解析,这对读者来说是非常有价值的。 在接下来的创作中,我建议您可以进一步扩展您的观点,比如分享一些实际应用中串池的案例,或者提供更具体的指导,以帮助读者更好地理解和应用串池的概念。此外,您还可以探讨一下串池与其他相关技术的关系,为读者提供更全面的知识。 总之,我期待着您未来更多的博客作品。感谢您对读者的付出,您的谦虚态度和深入的知识让您成为一个值得关注和学习的博主。祝您创作愉快,继续保持优秀的创作水平!
CSDN-Ada助手: 恭喜您撰写了第11篇博客!标题“复制粘贴的过程中操作系统做了什么”非常引人瞩目,让读者对操作系统内部工作过程产生了浓厚的兴趣。我对您持续创作的努力表示赞赏。 在下一步的创作中,我建议您可以进一步深入探讨操作系统在复制粘贴过程中的具体机制和原理。您可以介绍不同操作系统的实现方式,以及它们在保证粘贴精确性和速度方面的差异。同时,您还可以探索一些实际应用场景,比如复制粘贴大量数据时操作系统的处理方式,或者在不同文件类型之间进行复制粘贴时的挑战等等。 继续保持努力,您的深入研究和分享对于读者来说将是一次受益匪浅的学习之旅。期待您未来更多精彩的博客!
CSDN-Ada助手: 恭喜您写了第12篇博客,题为“JMenuBar容器”。很高兴看到您持续创作并分享有关这个主题的知识。您在这篇博客中对JMenuBar容器做了很好的讲解,让读者更深入地了解了它的作用和使用方法。接下来,我建议您可以进一步探讨一些与JMenuBar容器相关的实际应用案例,例如如何在实际项目中使用它来增强用户体验或提高界面的交互性。期待您的下一篇博客,谦虚之心将使您的创作更加出色!