python爬虫案例学习&&分析

狙个栗子
 已于 2023-11-30 15:21:26 修改
已于 2023-11-30 15:21:26 修改
 阅读量475
阅读量475
 收藏
收藏
 点赞数
1
点赞数
1
已于 2023-11-30 15:21:26 修改
阅读量475
收藏

 点赞数
1
点赞数
1
于 2022-10-30 23:41:02 首次发布

python爬虫案例分析
声明:本文仅供学习参考,请勿用作其他用途
0x01.什么是python爬虫
就是一段模拟浏览器向目标站点发起请求的自动抓取互联网站点资源的python程序
0x02.声明
1.本文仅供学习使用,请勿用作其他非法用途
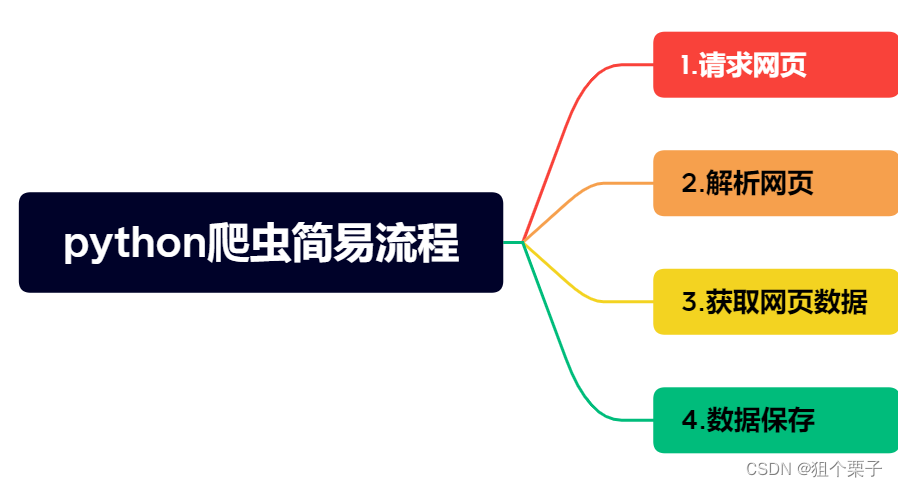
0x03.python爬虫案例
3-1.python爬虫自动爬取小说
<1>.爬取单章小说
在编写爬取代码之前,我们先来了解,解析数据的三种方式: css xpath re
什么时候使用xpath和css;当得到数据,有标签的时候用css,没有办法直接对于字符串数据进行提取
1.css选择器:根据标签属性提取数据
2.xpath:根据标签节点提取数据
3.re:当你无法用标签获取数据的时候,就用正则,可以直接对字符串数据进行提取
CSS&&Xpath
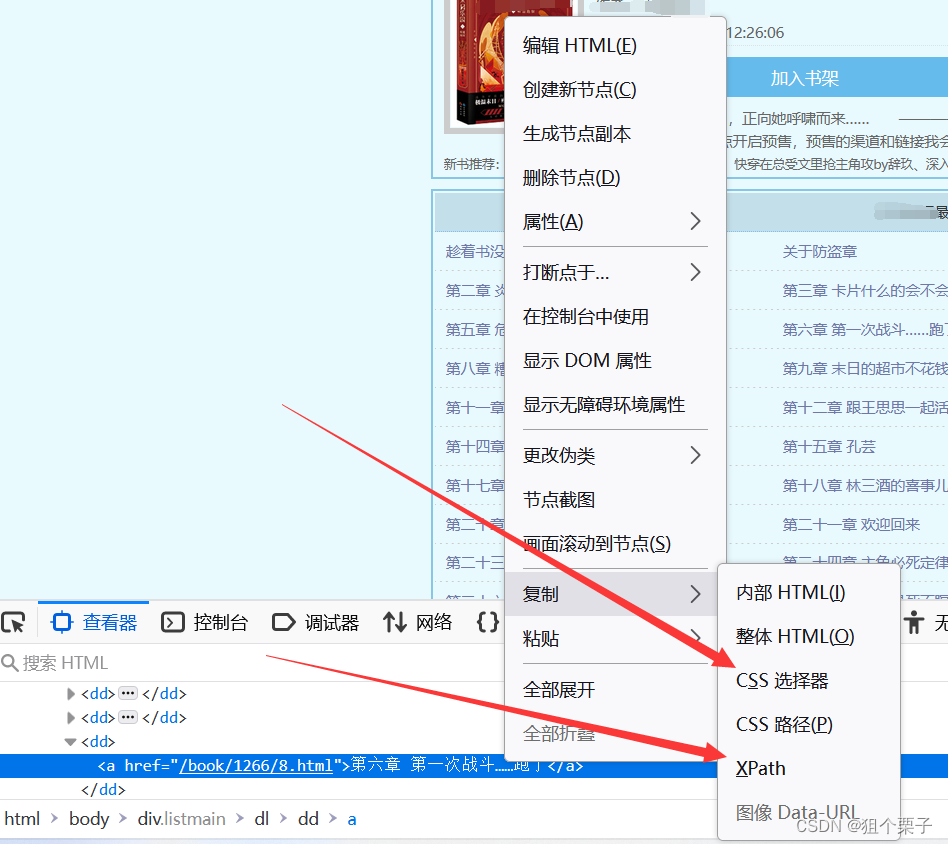
re:匹配相应字段内容 ----->re.findall(‘<li><a href=“(.*?)”>.*?</li>’,response.text)
pycharm上展示
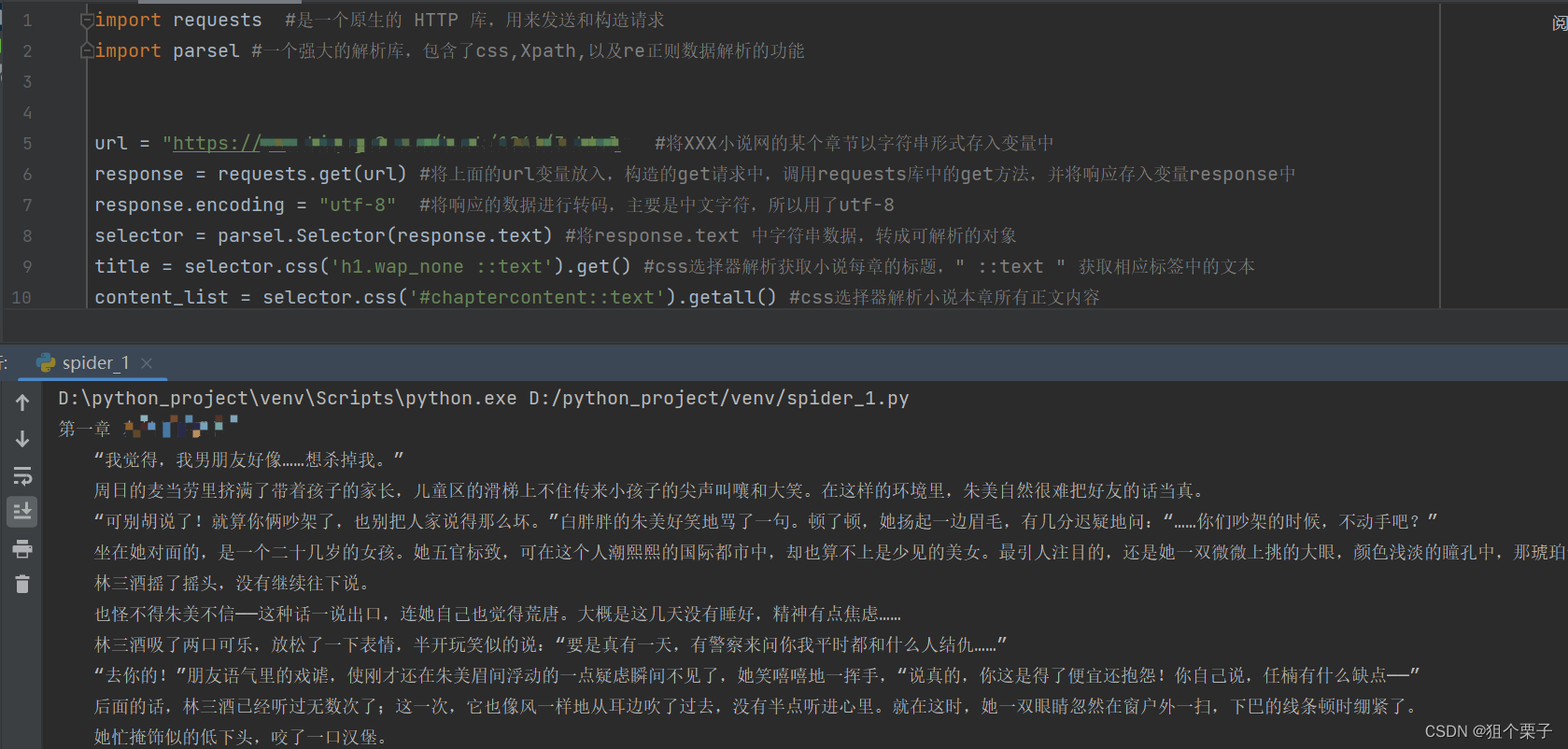
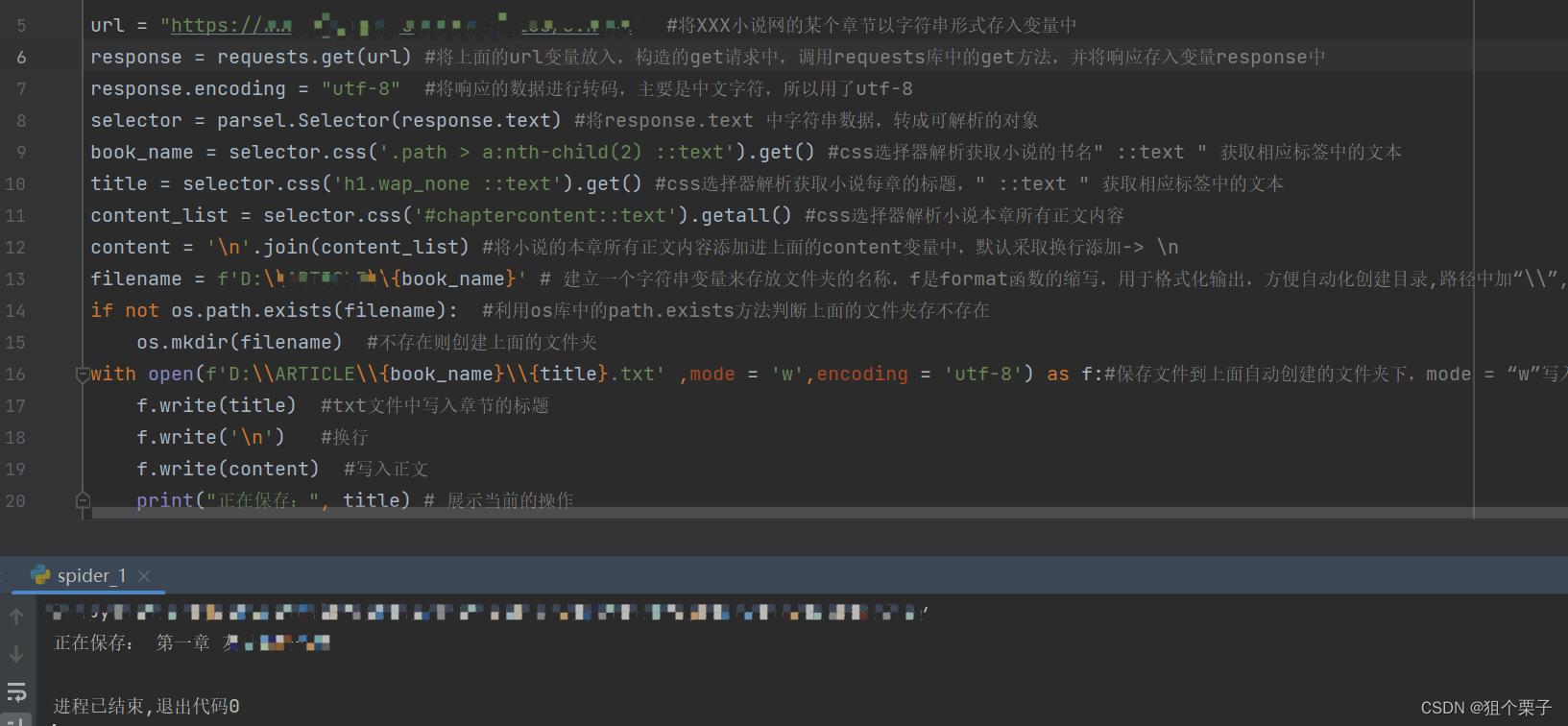
import requests #是一个原生的 HTTP 库,用来发送和构造请求
import parsel #一个强大的解析库,包含了css,Xpath,以及re正则数据解析的功能
url = "https://www.biquge9.com/book/1266/3.html" #将XXX小说网的某个章节以字符串形式存入变量中
response = requests.get(url) #将上面的url变量放入,构造的get请求中,调用requests库中的get方法,并将响应存入变量response中
response.encoding = "utf-8" #将响应的数据进行转码,主要是中文字符,所以用了utf-8
selector = parsel.Selector(response.text) #将response.text 中字符串数据,转成可解析的对象
title = selector.css('h1.wap_none ::text').get() #css选择器解析获取小说每章的标题," ::text " 获取相应标签中的文本
content_list = selector.css('#chaptercontent::text').getall() #css选择器解析小说本章所有正文内容
content = '\n'.join(content_list) #将小说的本章所有正文内容添加进content变量中,默认采取换行添加-> \n
print(title+'\n'+content)
效果 1 看这
保存数据内容到文件中如下
import requests #是一个原生的 HTTP 库,用来发送和构造请求
import parsel #一个强大的解析库,包含了css,Xpath,以及re正则数据解析的功能
import os #该库提供通用的、基本的操作系统交互功能
url = "https://www.XXX.com/book/XXX/3.html" #将XXX小说网的某个章节以字符串形式存入变量中
response = requests.get(url) #将上面的url变量放入,构造的get请求中,调用requests库中的get方法,并将响应存入变量response中
response.encoding = "utf-8" #将响应的数据进行转码,主要是中文字符,所以用了utf-8
selector = parsel.Selector(response.text) #将response.text 中字符串数据,转成可解析的对象
book_name = selector.css('.path > a:nth-child(2) ::text').get() #css选择器解析获取小说的书名" ::text " 获取相应标签中的文本
title = selector.css('h1.wap_none ::text').get() #css选择器解析获取小说每章的标题," ::text " 获取相应标签中的文本
content_list = selector.css('#chaptercontent::text').getall() #css选择器解析小说本章所有正文内容
content = '\n'.join(content_list) #将小说的本章所有正文内容添加进上面的content变量中,默认采取换行添加-> \n
filename = f'D:\\XXX\\{book_name}' # 建立一个字符串变量来存放文件夹的名称,f是format函数的缩写,用于格式化输出,方便自动化创建目录,路径中加“\\”,是防止出现转义字符出现
if not os.path.exists(filename): #利用os库中的path.exists方法判断上面的文件夹存不存在
os.mkdir(filename) #不存在则创建上面的文件夹
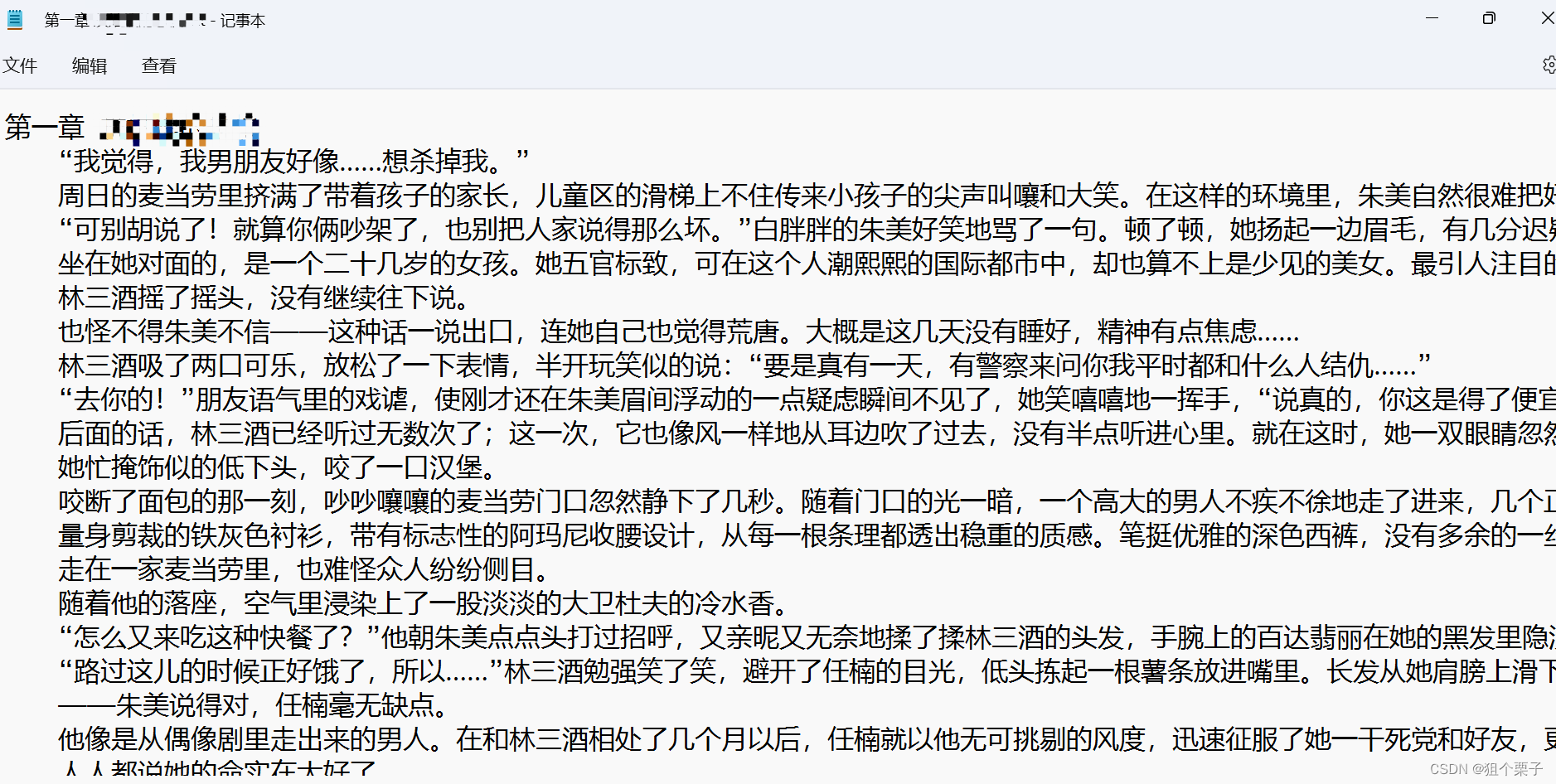
with open(f'D:\\XXX\\{book_name}\\{title}.txt' ,mode = 'w',encoding = 'utf-8') as f:#保存文件到上面自动创建的文件夹下,mode = “w”写入数据
f.write(title) #txt文件中写入章节的标题
f.write('\n') #换行
f.write(content) #写入正文
print("正在保存:", title) # 展示当前的操作
效果 2 展示
<2>.爬取整本小说
import requests
import os
import parsel
import re
dir_url = "https://www.XXX.com/XXX/1266/" #小说的目录页的Url
headers = {
'User-Agent':'XXX'
} #加个伪装的UA
response = requests.get(dir_url,headers)
response.encoding = "utf-8"
link = re.findall('<dd><a href ="(.*?)">.*?</a></dd>', response.text)
Book_name = re.findall('<meta property="og:title" content="(.*?)"/>', response.text)[0]
filename = f'D:\\ARTICLE\\{Book_name}'
if not os.path.exists(filename):
os.mkdir(filename)
for index in link:
index_url = "https://www.biquge9.com" + index # Url拼接
response = requests.get(index_url,headers)
response.encoding = "utf-8"
selector = parsel.Selector(response.text)
title = selector.css('h1.wap_none ::text').get()
content_list = selector.css('#chaptercontent::text').getall()
content = '\n'.join(content_list)
with open(f'D:\\ARTICLE\\{Book_name}\\{Book_name}.txt', mode='a', encoding='utf-8') as f:
f.write(title)
f.write('\n')
f.write(content)
f.write('\n')
print("正在保存:", title)
注意:数据解析中的标签样式(标题,正文),每个小说网页都不同,需要根据具体情况进行填入
3-2.python爬虫爬取单网页图片资源
实现原理:请求网页中源码,并将源码中的<img>标签内图片URL链接通过正则保存到一个列表内,后面再通过请求这个图片URL,将请求的响应通过二进制形式保存进已随机数命名的jpg格式文件内
源码如下
# -*- coding:utf-8 -*-
# 请求网页
import os
import time
import random
import requests
import re
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0'}
response = requests.get('https://XXXX.com/XXXX.html', headers=headers)
html = response.text
urls = re.findall(r'<img[^>]+src=[\'"]([^\'"]+)[\'"][^>]*>', html) # 正则表达式解析网页图片资源
urls = [item for item in urls if not re.match(r"^data", item)]
# 保存图片
for url in urls:
time.sleep(1) # 延时1秒
# 图片名字
random_str = ''.join(random.choices('abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789', k=6)) # 生成一个长度为6的随机字符串,包含大小写字母和数字
response = requests.get(url, headers=headers)
with open(f"images/{random_str}.jpg", 'wb') as f: # 以2进制形式写入文件名
f.write(response.content)















 678
678










 暂无认证
暂无认证












 到【灌水乐园】发言
到【灌水乐园】发言










M5K2: 同问,有没有找到2.10版本的镜像
掉色的熊猫: 现在这个镜像能不能下载到2.9,2.10的
掉色的熊猫: 你这镜像是那个版本的呀。
JinxDream_Life: 解密时p=1009 q=1013 e=13 ,输入后显示逆元d为78469为非质数,输入C后解密结果与明文不符
........6: 这个最后的注册成功的框为什么没有弹出啊