【2020东京奥运会】奥运榜单以及各国参赛运动员数据可视化~
最新推荐文章于 2024-05-17 10:12:16 发布

AwesomeTang
 最新推荐文章于 2024-05-17 10:12:16 发布
最新推荐文章于 2024-05-17 10:12:16 发布
 阅读量1.3w
阅读量1.3w
 收藏
46
收藏
46
 点赞数
6
点赞数
6
最新推荐文章于 2024-05-17 10:12:16 发布
阅读量1.3w
收藏
46

 点赞数
6
点赞数
6
项目
本文中的代码是基于notebook写的,可以访问https://www.heywhale.com/mw/project/61015e73aca24600179ec778获取完整notebook.
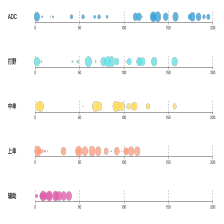
奖牌榜数据
通过咪咕视频的接口获取奖牌榜单的数据,貌似也没做什么反爬虫,直接就可以获取到数据:
import requests
rank_url = 'https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609'
data = requests.get(rank_url).json()数据处理,将json数据转化为dataframe:
df = pd.DataFrame()
for item in data['body']['allMedalData']:
df = df.append([[
item['rank'],
item['countryName'],
item['goldMedalNum'],
item['silverMedalNum'],
item['bronzeMedalNum'],
item['totalMedalNum']]])
df.columns = ['排名', '国家', '金牌', '银牌', '铜牌', '奖牌']
df = df.reset_index(drop=True)
使用plotly展示榜单前30个国家:
import plotly.graph_objects as go
from plotly.colors import n_colors
import numpy as np
np.random.seed(1)
colors = n_colors('rgb(225,255,255)', 'rgb(255,192,203)', 10, colortype='rgb')
fig = go.Figure(
data=[go.Table(
columnwidth=[20, 80, 80, 80, 80],
header=dict(values=["<span style='font-size:16px;color:#fff;font-weight:bold';>{}</span><br>".format(c) for c in df.columns],
line_color='darkslategray',
fill_color='rgb(255,0,0)',
align=['center'],
# font=dict(color='white', size=13),
height=40),
cells=dict(values=df.head(30).T,
line_color='darkslategray',
fill=dict(color=[colors, 'white']),
align=['center'],
font_size=13,
height=30))
])
fig.update_layout(
height=1200,
title_text="<span style='font-size:20px;color:#0000FF;font-weight:bolder';>2020东京奥运会奖牌榜</span><br><span style='font-size:12px;color:#C0C0C0';>更新时间:{}</span>".format(update_time),
)
fig.show() 运动员数据
运动员数据
- 2020年东京奥运会全部参赛人员名单数据来自奥委会官网( https://olympics.com/tokyo-2020/olympic-games/zh/results/all-sports/athletes.htm);
- 整体数据来看,总共206个国家或地区的代表团共11309名选手参赛,比2016年里约奥运会的11180人多出129人,为史上参赛人数最多的一届奥运会;
获取国家简称和项目的中文名称对应表:
# 获取国家简称对应的中文名称
noc = 'https://olympics.com/tokyo-2020/olympic-games/zh/results/all-sports/nocs-list.htm'
r = requests.get(noc)
para = r'</li>.*?country="(?P<简称>.*?)">.*?<div class="mx-auto font-weight-bold">(?P<中文名称>.*?)</div>'
patterns = re.compile(para)
noc_dict = {}
for k, v in patterns.findall(r.text):
noc_dict[k] = v
# 获取项目简称对应的中文代码
sports = 'https://olympics.com/tokyo-2020/zh/sports/'
r = requests.get(sports)
para = r'<div class="tk-disciplines__picto tk-picto-(.*?)"></div>\s+.*?title">\s+(.*?)\s+'
patterns = re.compile(para)
sports_dict = {}
for k, v in patterns.findall(r.text):
sports_dict[k.upper()] = v获取运动员数据
athlete_url = 'https://olympics.com/tokyo-2020/olympic-games/zh/results/all-sports/zzje001a.json'
data = requests.get(athlete_url).json()
athletes_df = pd.DataFrame(columns=['姓名', '国家', '项目'])
for item in data['data']:
athletes_df = athletes_df.append(
[{'姓名': item['name'], '国家':noc_dict[item['noc']], '项目':sports_dict[item['dis']]}])
athletes_df = athletes_df.reset_index(drop=True)
按国家维度聚合统计:
df_t = athletes_df.groupby(['国家', '项目'])['姓名'].count().reset_index()
df_t.columns = ['国家', '项目', '人数']
data = []
country = []
for idx, row in df_t.iterrows():
if row['国家'] in country:
data[-1]['children'].append(dict(name=row['项目'], value=row['人数']))
else:
data.append(dict(name=row['国家'], children=[dict(name=row['项目'], value=row['人数'])]))
country.append(row['国家'])
tree = TreeMap(
init_opts=opts.InitOpts(
theme='light',
width='1000px',
height='600px',
# bg_color='rgb(0,0,0)'
))
tree.add(
"参赛人数",
data,
leaf_depth=1,
label_opts=opts.LabelOpts(position="inside", formatter='{b}:{c}名'),
levels=[
opts.TreeMapLevelsOpts(
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color="#555", border_width=4, gap_width=4
)
),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.6],
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.7, gap_width=2, border_width=2
),
),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.5],
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.6, gap_width=1
),
),
# opts.TreeMapLevelsOpts(color_saturation=[0.3, 0.5]),
],
)
tree.set_global_opts(
title_opts=opts.TitleOpts(title="2020东京奥运会参赛人数统计(国家/地区)", pos_left='center', title_textstyle_opts=opts.TextStyleOpts(color='#00BFFF', font_size=20)),
legend_opts=opts.LegendOpts(is_show=False)
)
tree.render_notebook()
按运动项目聚合统计:
df_t = athletes_df.groupby(['项目', '国家'])['姓名'].count().reset_index()
df_t.columns = ['项目', '国家', '人数']
data = []
event = []
for idx, row in df_t.iterrows():
if row['项目'] in event:
data[-1]['children'].append(dict(name=row['国家'], value=row['人数']))
else:
data.append(dict(name=row['项目'], children=[dict(name=row['国家'], value=row['人数'])]))
event.append(row['项目'])
tree = TreeMap(
init_opts=opts.InitOpts(
theme='light',
width='1000px',
height='600px',
# bg_color='rgb(0,0,0)'
))
tree.add(
"参赛人数",
data,
leaf_depth=1,
label_opts=opts.LabelOpts(position="inside", formatter='{b}:{c}名'),
levels=[
opts.TreeMapLevelsOpts(
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color="#555", border_width=4, gap_width=4
)
),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.6],
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.7, gap_width=2, border_width=2
),
),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.5],
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.6, gap_width=1
),
),
# opts.TreeMapLevelsOpts(color_saturation=[0.3, 0.5]),
],
)
tree.set_global_opts(
title_opts=opts.TitleOpts(
title="2020东京奥运会参赛人数统计(项目)",
pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(color='#00BFFF', font_size=20)
),
legend_opts=opts.LegendOpts(
is_show=False
)
)
tree.render_notebook()
主要国家各项目参数人数对比
pie = Pie(
init_opts=opts.InitOpts(
theme='light',
width='1000px',
height='800px',
)
)
titles = [dict(
text='2020东京奥运会各国主要项目参赛运动员比例',
left='center',
top='0%',
textStyle=dict(
color='#000',
fontSize=20)
)
]
for i, c in enumerate(country_list):
d = df_t[df_t['国家'] == c].reset_index()
data_pair = []
else_num = 0
for idx, row in d.iterrows():
if idx < 5:
data_pair.append(
opts.PieItem(
name=row['项目'],
value=row['人数'],
label_opts=opts.LabelOpts(
is_show=True, formatter='{b}:{d}%')
)
)
else:
else_num += row['人数']
data_pair.append(
opts.PieItem(
name='其他',
value=else_num,
label_opts=opts.LabelOpts(
is_show=True, formatter='{b}:{d}%')
)
)
pos_x = '{}%'.format(int(i / 4) * 33 + 16)
pos_y = '{}%'.format(i % 4 * 24 + 15)
titles.append(
dict(
text=c+' ',
left=pos_x,
top=pos_y,
textAlign='center',
textVerticalAlign='middle',
textStyle=dict(
color='#00BFFF',
fontSize=12)
)
)
pie.add(
c,
data_pair,
center=[pos_x, pos_y],
radius=['8%', '12%']
)
pie.set_global_opts(
legend_opts=opts.LegendOpts(is_show=False),
title_opts=titles
)
pie.render_notebook()

















 904
904











 Python领域优质创作者
Python领域优质创作者





















 到【灌水乐园】发言
到【灌水乐园】发言












Liberty812: 升序和降序那两个是不是写差东西呀
ζ珊大宝~: 请问最后一个的多个环形图的代码for _, row in t_data.iterrows(): if idx % 2 == 0: x = 30 y = int(idx / 2) * 22 + 18 else: x = 70 y = int(idx / 2) * 22 + 18 idx += 1 pos_x = str(x) + '%' pos_y = str(y) + '%' pie.add( row['Sport'], [[row['region'], row['Event_x']], ['其他国家', row['Event_y'] - row['Event_x']]], center=[pos_x, pos_y], radius=[70, 100], label_opts=new_label_opts())什么意思哇
GouDX: 不出现地图是啥情况呀
Penna_a: 请教下Gauge仪表盘颜色设置成渐变色应该怎么操作呢?
Nemo-Wang: from pyecharts.datasets import register_url报错是为什么啊