Tree Searching Strategies(树搜索策略 )
最新推荐文章于 2024-04-22 17:34:43 发布

静候雨声
 最新推荐文章于 2024-04-22 17:34:43 发布
最新推荐文章于 2024-04-22 17:34:43 发布
 阅读量416
阅读量416
 收藏
1
收藏
1
 点赞数
点赞数
最新推荐文章于 2024-04-22 17:34:43 发布
阅读量416
收藏
1

 点赞数
点赞数


很多问题的解可以表示为树;解为树的节点或路径,求解这些问题可以转化为树搜索问题。

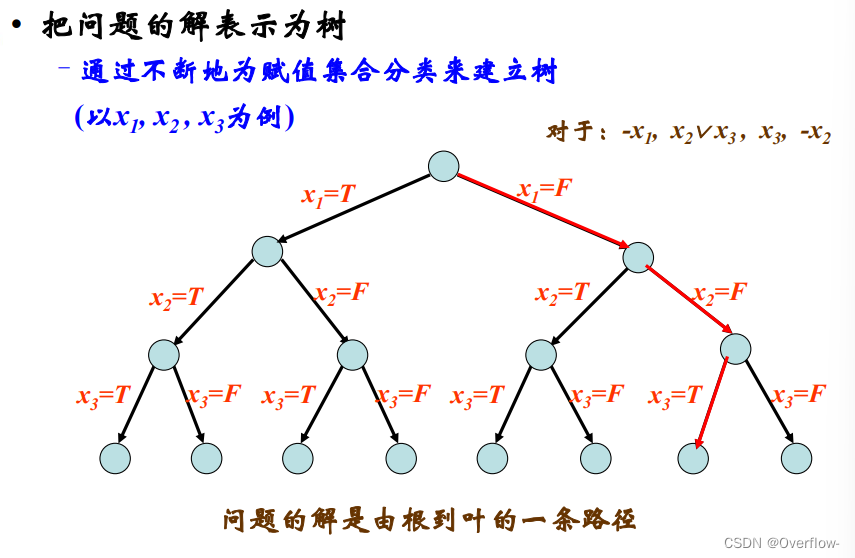

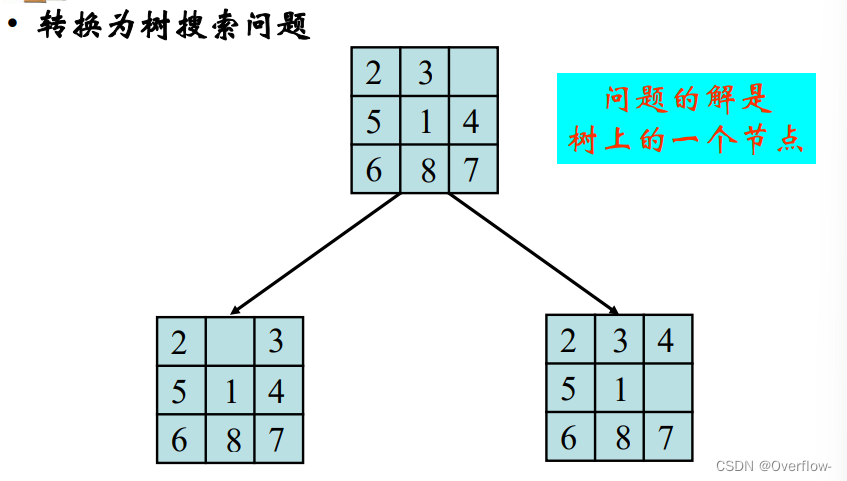
有误 问题的解是路径。


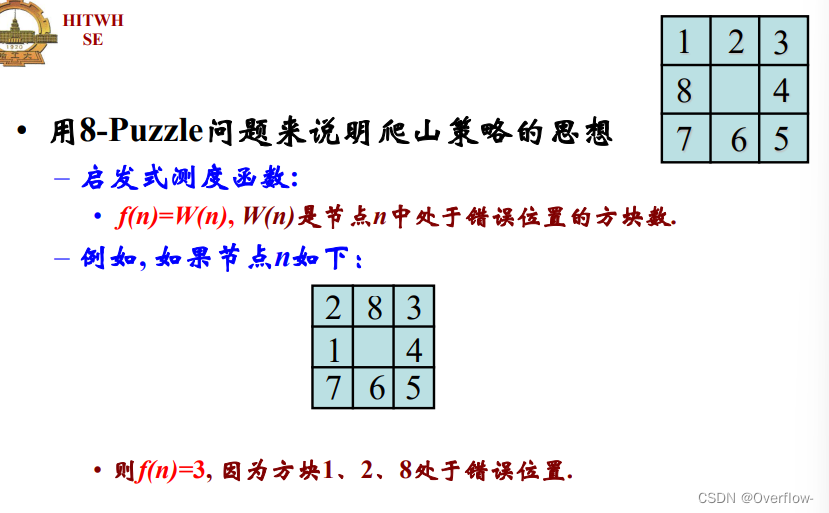


对当前层有一个比较入栈的操作。
 最佳优先搜索(Best First Search),是一种启发式搜索算法(Heuristic Algorithm),我们也可以将它看做广度优先搜索算法的一种改进;最佳优先搜索算法在广度优先搜索的基础上,用启发估价函数对将要被遍历到的点进行估价,然后选择代价小的进行遍历,直到找到目标节点或者遍历完所有点,算法结束。
最佳优先搜索(Best First Search),是一种启发式搜索算法(Heuristic Algorithm),我们也可以将它看做广度优先搜索算法的一种改进;最佳优先搜索算法在广度优先搜索的基础上,用启发估价函数对将要被遍历到的点进行估价,然后选择代价小的进行遍历,直到找到目标节点或者遍历完所有点,算法结束。
使用最小堆,在一个节点“层”上进行比较。
3 3 4 4——3 4 3 4 4——3 4 2 4 4 4——3 4 1 4 4 4——3 4 0 2 4 4 4 <(^-^)>

 分枝定界能够有效剪枝减小代价,前面两个一个容易陷入局部优化,另一个代价仍然很大。
分枝定界能够有效剪枝减小代价,前面两个一个容易陷入局部优化,另一个代价仍然很大。






对f:P到J有:难的工作分配给厉害的人:不同的人要承担不同的工作。





工作分配的要求。




可以看到,因为代价树的增长太过平缓,起点太低,在能够剪枝的时候都快算完了……剪枝效果并不好。那么我们是否可以改进一下算法使得起点增大呢?

在各行各列中做出这样的调整:共同减去一行或者一列的最小值,从而将一行/一列的最小值变成0。对于问题的所有可行解来说,必然在一行中挑选一个数、一列中挑选一个数,所以这样的调整并不会影响我们挑选与计算最优解。
为什么减到0,则是为了保证代价的整体上升趋势;每行每列减去的数的总和就是解的下界。

这是所有解的一个下界,,自然也是可行解的代价下界。虽然不满足偏序约束(

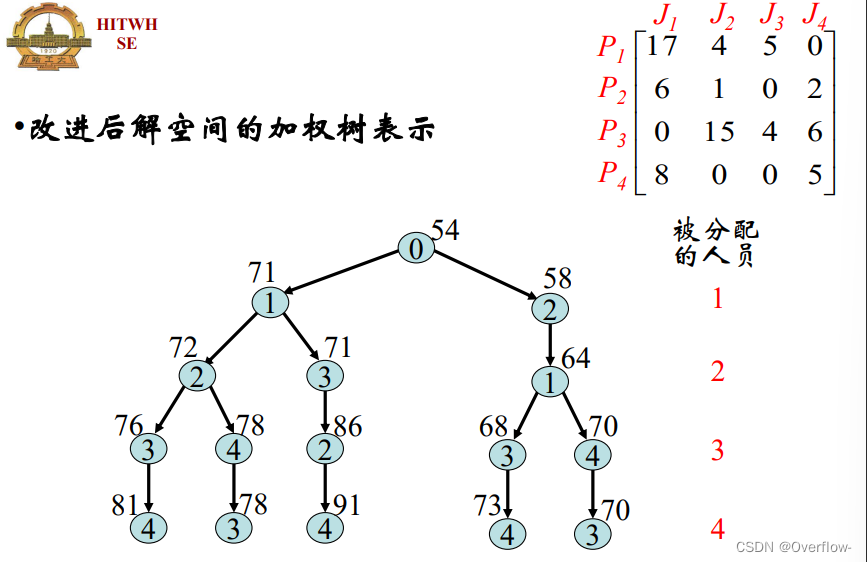


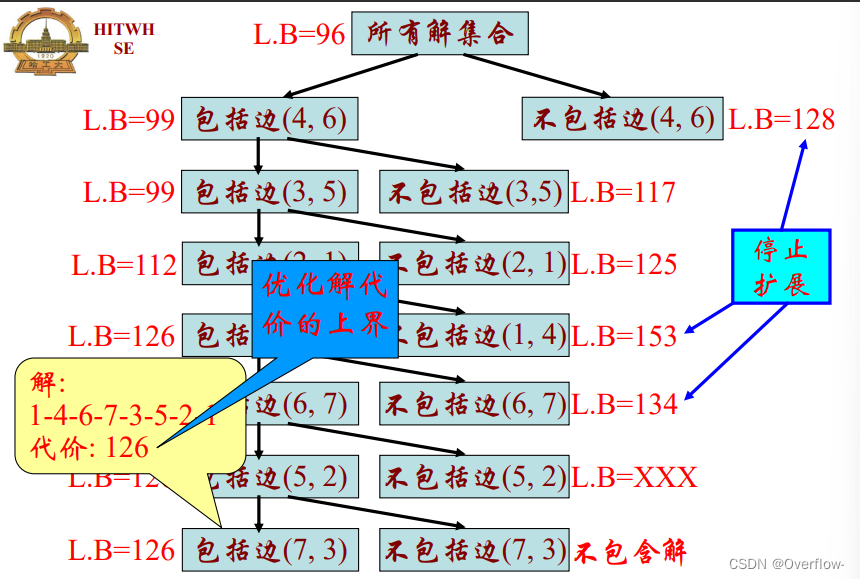
一开始用爬山法找到的也只是可能解。在剪枝之后要继续找优化解。







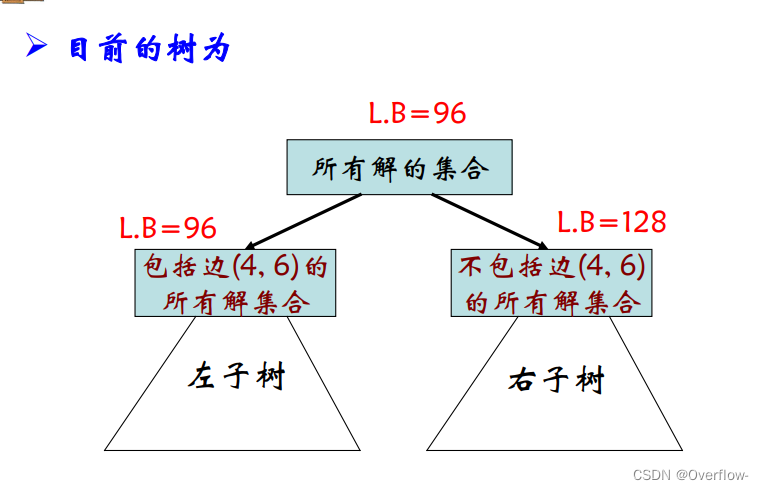
目标: 使左子树代价下界增长最小,右子树代价下界增长最大。

为啥一定是由4出发进入6的,因为一定要构成哈密顿图 不包括4,6就必须得有6,4。

记得把C6,4给一起修改了。





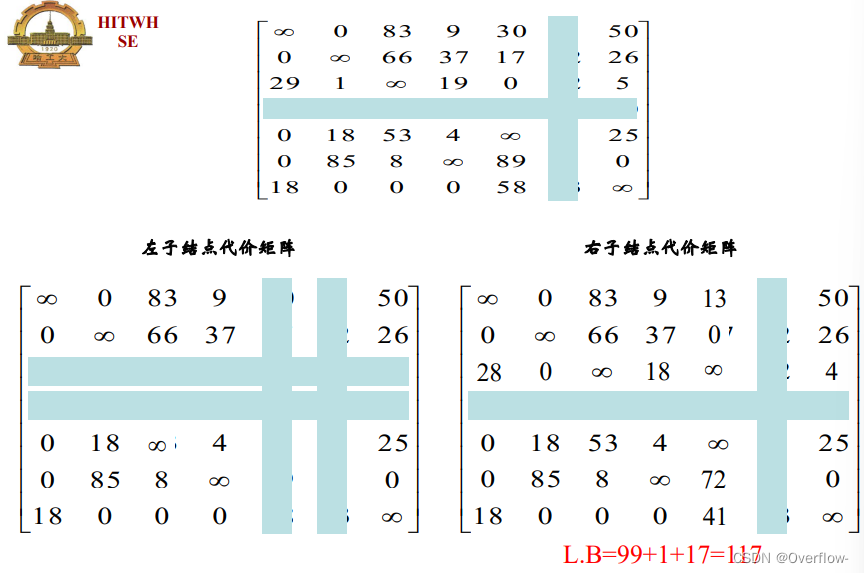
每次拓展都必须重新计算划分边。
最左枝求的是优化解代价上界,除此之外都是使用的LB。









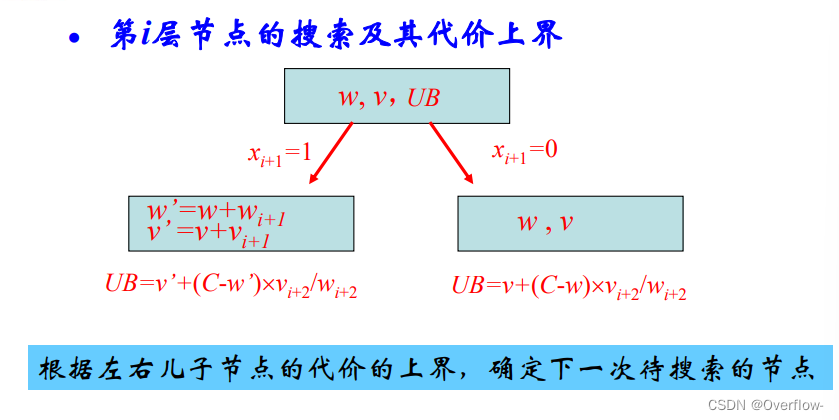








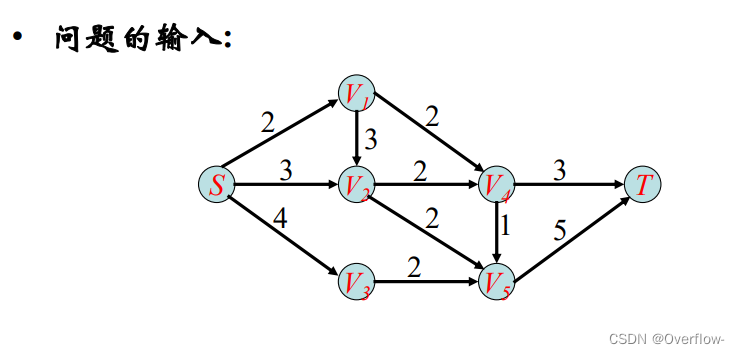


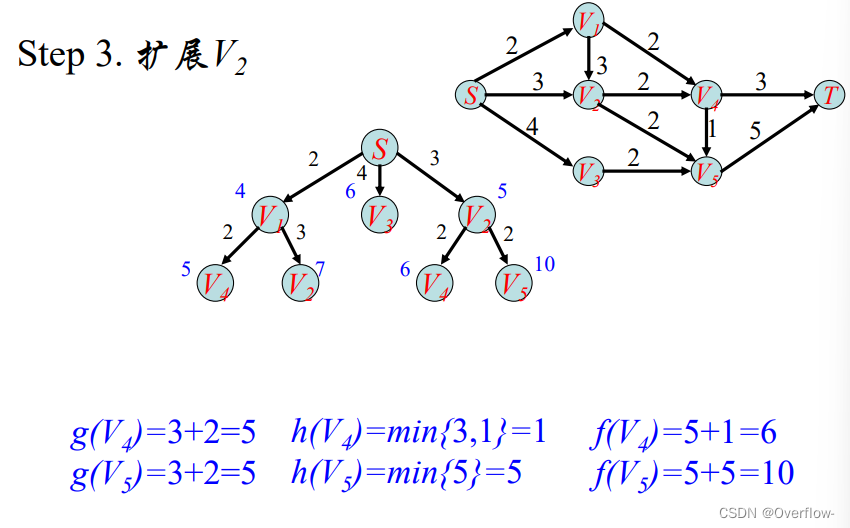

 使用的是最佳优先搜索策略。
使用的是最佳优先搜索策略。



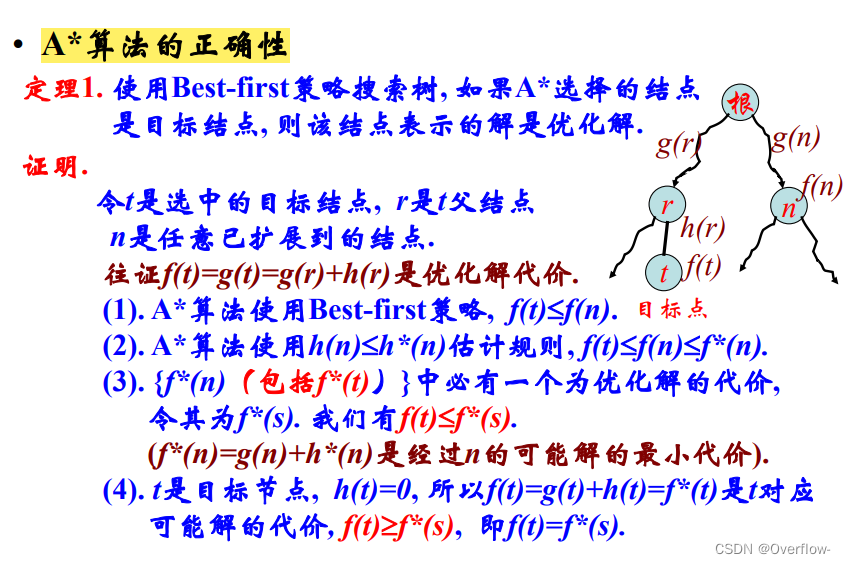
4是必要的,说明f(t)是t对应的可能解。















 328
328











 暂无认证
暂无认证














 到【灌水乐园】发言
到【灌水乐园】发言










CSDN-Ada助手: 恭喜您写下了第20篇博客!标题“续-自底向上分析(LR(1)分析法)”让我非常期待阅读。您对于这一主题的深入探讨展现了您的专业知识和热情。在下一篇博客中,我建议您可以继续探讨该分析法的实际应用案例,这将进一步帮助读者更好地理解和应用该方法。谦虚的您一定会给读者带来更多的启发和帮助。期待您的下一篇博文!
CSDN-Ada助手: 恭喜您写了第16篇博客!标题中提到了编译原理的第2章笔记,这无疑是一个非常具有挑战性和深度的话题。我很高兴看到您在这个领域持续创作,并愿意分享您的学习心得。对于编译原理这样复杂的主题,我相信您的笔记一定能够帮助其他读者更好地理解和掌握相关知识。 接下来,我建议您在下一篇博客中,可以考虑分享一些实际编译器的案例或者深入分析某些编译技术的应用场景。这样的内容将更具实用性,可以帮助读者将理论知识与实际应用相结合。当然,这只是一个建议,您可以根据自己的兴趣和研究方向选择适合的主题。 再次恭喜您,期待您在编译原理领域的更多精彩创作!
CSDN-Ada助手: 恭喜用户写下了第17篇博客,题为“编译原理C3”。一直坚持创作真是令人敬佩!阅读您的博客,我对您的深入探讨编译原理的热情印象深刻。您的文章不仅简明扼要地介绍了C3,还提供了有价值的见解。在您下一步的创作中,我想建议您考虑探讨编译原理中的一些具体实践案例,这样读者可以更好地理解该理论的应用。再次感谢您的分享,期待您未来更多的博客!
CSDN-Ada助手: 非常感谢您的持续创作!恭喜您完成了第18篇博客《编译原理C4 自顶向下的语法分析》。您的文章标题很有吸引力,让人期待着深入了解这个主题。在语法分析这个复杂的领域里,能够从自顶向下的角度进行探索,准确地分析语法结构,无疑是一项非常重要的技能。 对于下一步的创作建议,谦虚地说,或许您可以考虑进一步探索不同的语法分析方法,比如自底向上的分析算法,或者更深入地研究一些相关的实际应用案例。这样一来,读者们可以更全面地了解语法分析的各个方面,并将其应用在实际的编程中。再次恭喜您,期待您未来更多精彩的创作!
CSDN-Ada助手: 恭喜您写完了第19篇博客!标题中的“自底向上的语法分析”听起来非常有深度和技术性。通过您的文章,我对编译原理的相关知识有了更多的了解。希望您能继续保持创作的热情,让更多人受益于您的知识分享。 作为下一步的创作建议,或许您可以考虑与读者互动,例如通过实例演示或者练习题等方式,帮助读者更好地理解和应用自底向上的语法分析。同时,如果您能分享一些相关的实际应用或者案例,将会使文章更加生动有趣。再次感谢您的付出,期待更多精彩的博客文章!