Python爬虫设计思路
最新推荐文章于 2024-04-28 11:22:36 发布
置顶
小雨喳
 最新推荐文章于 2024-04-28 11:22:36 发布
最新推荐文章于 2024-04-28 11:22:36 发布
 阅读量5.2k
阅读量5.2k
 收藏
22
收藏
22
 点赞数
6
点赞数
6
最新推荐文章于 2024-04-28 11:22:36 发布
阅读量5.2k
收藏
22

 点赞数
6
点赞数
6

Python爬虫设计思路
一、爬虫架构

- 爬虫调度端:一般指的入口函数,发起动作的入口。
- URL管理器:存放待爬取网站的URL和已爬取过的URL的功能(python内存、关系数据库、缓存数据库)。
- 网页下载器:进行页面爬取的功能(Requests、urllib2)。
- 网页解析器:对爬取下来的数据进行清洗(BeautifulSoup)。
- 价值数据:存放意向数据。
二、运行流程
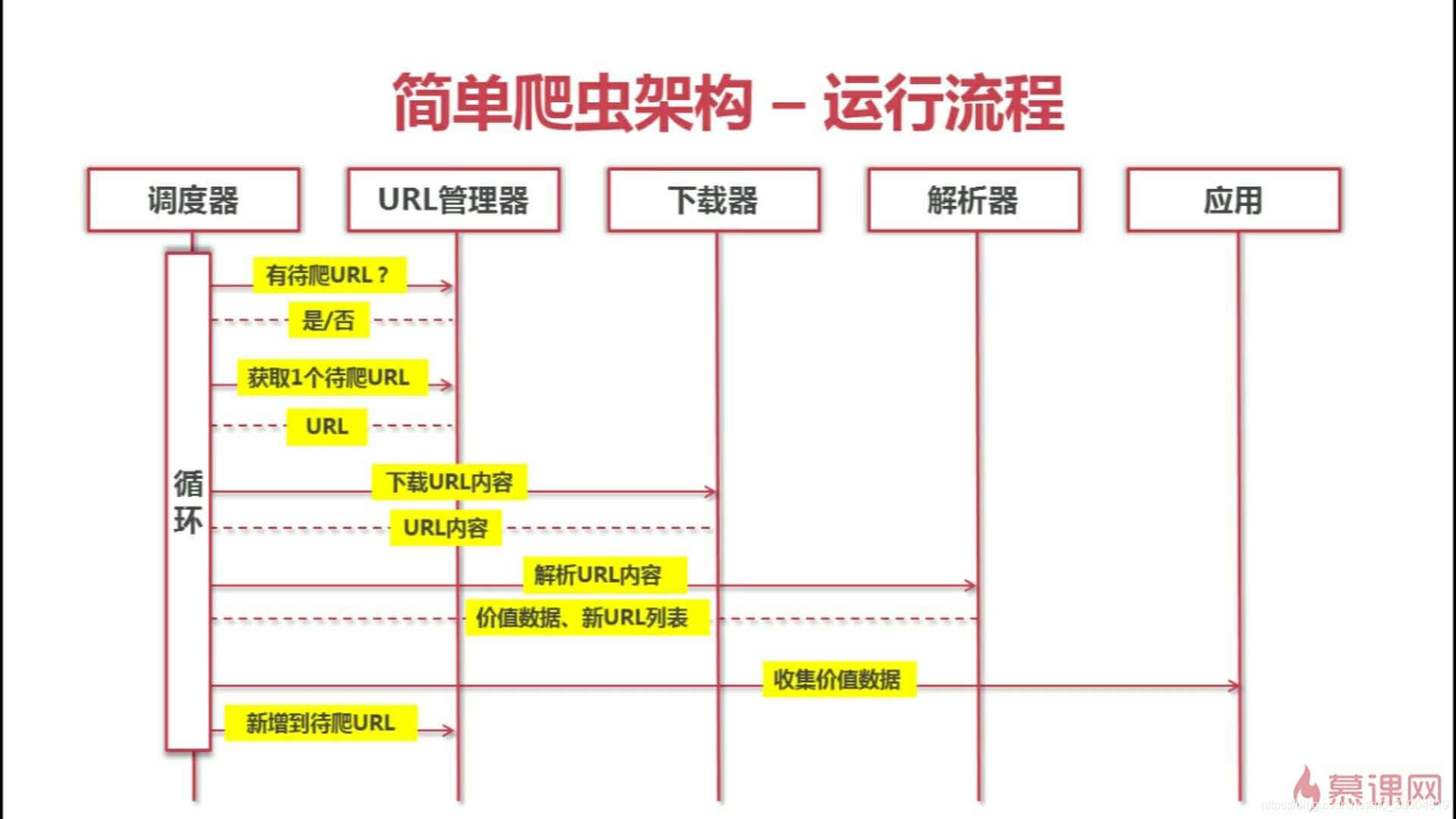
三、分析目标
















 916
916










 暂无认证
暂无认证

























 到【灌水乐园】发言
到【灌水乐园】发言










追赶sun: 就照您的代码只改了网址,运行的xls文件什么也没有,您可以解答一下吗,这是我想爬取的网址:https://tjj.sh.gov.cn/tjnj/nj22.htm?d1=2022tjnj/C0110.htm
yinpan00: 当做包导入为什么get方法找到不
CSDN-Ada助手: 多亏了你这篇博客, 解决了问题: https://ask.csdn.net/questions/8014557, 请多输出高质量博客, 帮助更多的人
companyIU: 有个问题唉,就是安装docker是配置了使用阿里云镜像仓库吗,那就说明镜像来源于阿里云镜像仓库啊,那还要镜像加速器干甚,不懂
岌岌卜: 写得真的很好,但是文件不知道保存到哪里去辽